Open Cloud & Big Data 2012 참석 후기
스마트 폰 앱과 스타트업 기업의 인프라와 대기업의 대용량 데이터 처리가 더불어 이슈화 되면서 Cloud와 Big Data는 최근 가장 관심있는 주제어가 아닌가 생각이 된다. 데이터베이스 연구실에서 연구활동을 하면서 RDBMS 를 주력으로 사용하던 예전과 달리 최근의 데이터 처리 트랜드와 기술적 접근 방법을 얻기 위해서 이번 컨퍼런스에 참석하게 되었다. 같은 날에 inews24에 열리는 3Big Technology와 두가지 컨퍼런스 중에 어떤 것을 참석할지 심각하게 고민을 하고 있었다. 3Big Technology에서는 Big Data, Cloud, HTML5 관련 사례를 발표하는데 발표자와 후원자들이 굵직한 벤더들(Oracle, IBM, SK, 현대 등)이였기 때문이다. 하지만 결국은 KT cloudware에서 주최하는 “Open Cloud & Big Data 2012”에 참석을 하기로 결정했다. 이 컨퍼런스를 참석하게 된 가장 큰 이유는 바로 “Open Source 활용 사례”이다. 즉, 항상 서울까지 멀리 컨퍼런스를 참석하고 내려가서 종이 한장만 남는게 아니라, 실제 프로젝트에 도입하고 연구할 수 있는 팁을 얻기 위해서 였다. Open Source는 바로 내려와서 내가 연구실에서 테스트 서버를 여러대 묶어서 인프라를 만들어 볼 수 있다고 생각했다.
이 포스팅은 NexR과 KT cloudware에서 발표한 내용을 요약하고 있지 않다. 연구실 대표로 컨퍼런스에 참석했고, 그 날의 agenda를 리뷰 형식으로 후기를 작성한 포스팅이다. 실제 배운 내용은 연구실에서 가상화를 구축하고 난 다음에 Cloud와 Big data라는 블로그의 다른 메이 카테고리에서 새롭게 다룰것이다.
컨퍼런스는 무료 컨퍼런스라 agenda를 포함한 출력물 이 외에는 책자하나 없었고, 중식도 서비스되지 않았다. 그래서 교육마치고 부산까지 내려오는 길에 책자가 없어서 조금 어색하고 서운하긴 했지만, 세션 발표를 하여주신 분들은 실제 NexR의 엔지니어들로 KT Cloud 를 구축하는데 참여하시고 그 사례와 오픈소스의 장점과 문제점을 정말 엔지니어의 시각으로 발표해주셨기 때문에 앞으로 어떻게 인프라를 구축해야할지 좋은 정보를 많이 들을 수 있었다.
각 세션들은 그렇게 길지 않았다. 컨퍼런스의 전체 프로그램은 다음과 같았다.
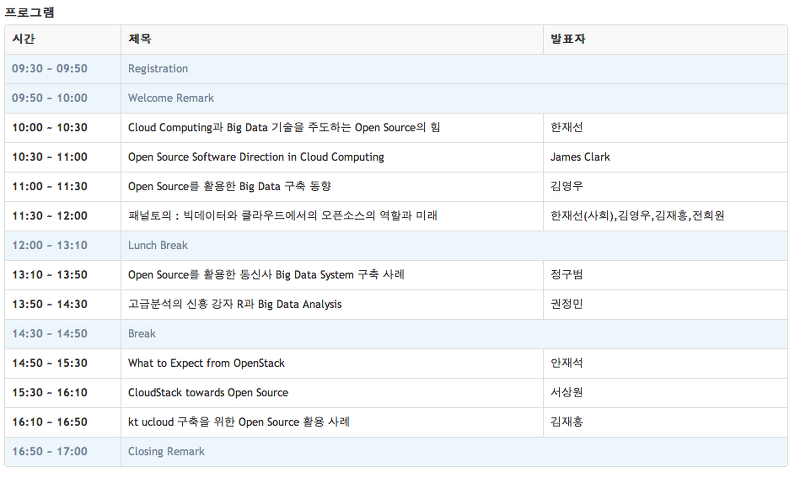
Cloud Computing과 Big Data 기술을 주도하는 Open Source의 힘
첫번째 키노트는 NexR 한재선 CEO (@jaesun_han) 께서 “Cloud Computing과 Big Data 기술을 주도하는 Open Source의 힘”에 대해서 발표를 해주셨다. 트윗사진과 다르게 샤프한 외모에 목소리까지 선명해서 짧은 키노트 시간이였지만 전달받은 내용이 명확했다.
키노트자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_Bi

역시나 최근 빅데이터에서는 Hadoop을 제외하고는 이야기가 되지 않는 것 같다. 더구나 오픈소스 사례이다보다 당연히 Hadoop에 대해서 말씀해주셨고, Hadoop의 echo system에 대한 자료, 실제 KT의 uCloud 서비스에서 사용된 오픈소스의 사례를 발표해주셨다.
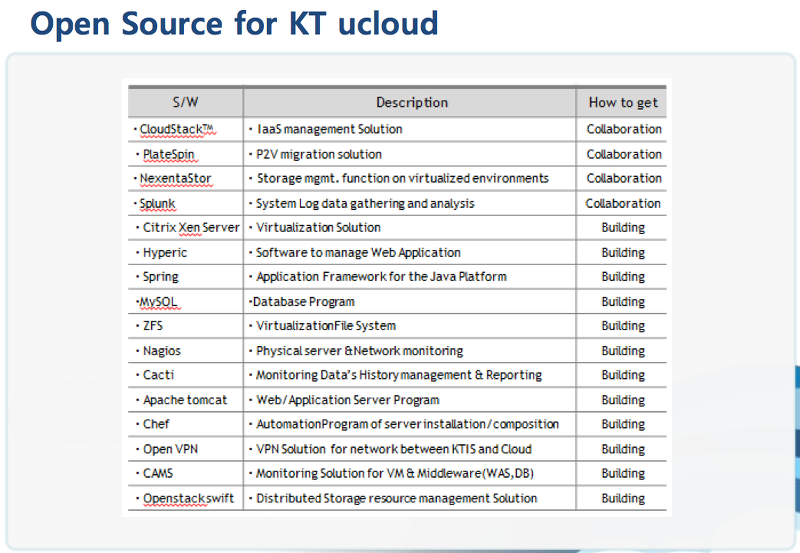
이 자료만 보아도 Cloud 인프라를 구축하기 위해서 어떤 오픈 소스가 필요한지 알 수 있을 것 같다는 생각이 들었다. 그리고 SDEC 2011에서 NexR의 통신사의 대용량 데이터를 처리하기 위해서 Hive라는 것을 도입하고, HQL(Hive에서 사용하는 Query Language)를 예로 보여주면서 발표해 주신게 너무 인상적이였는데, NexR에서 Hive는 이미 중요한 Core를 차지하고 있고 회사에서 정식으로 comitter를 양성하고 투자하고 있다고 하였다. Hive는 SQL like한 인터페이스로 복잡한 Map Reduce를 작성하는 프로그램을 대처할 수 있기 때문여 개발에 매우 효율성을 가져올 수 있다고 말해주었다. 실제 업체 대부분의 레거시 데이터관리 시스템은 RDBMS이고 이 시스템에서의 모든 인터페이스는 SQL 로 구성되어 있기 때문에 Big Data를 도입하더라도 존재하는 수천가지의 SQL을 모두 Map Reduce로 재작성하는 것이 거의 불가능 하다는 것이다. 이러한 이유로 SQL을 사용할 수 있다는 것은 매우 효과적이라고 볼 수 있다. 그리고 NexR에서 직접 오프소스 프로젝트를 등록해서 진행하고 있는 것이 있는데 RHive라는 것이다. github에 등록해서 오픈소스 프로젝트로 진행하고 있는데, 이것은 통계프로그램인 R과 Hive를 상호연동하는 프로젝트이다. 이번 컨퍼런스에 또하나 중요한 키워드로 R 이라는 것이 있다. R는 통계자료를 프로그래밍할 수 있는 함수형 언어이다. 빅 데이터 처리는 바로 빅 데이터 분석과 같은 말이라고 볼 수 있는데, 이렇게 분석을 하기 위해서 반드시 분석 프로그램이 필요하다. R는 그러한 분석을 처리할 수 있는 프로그래밍을 지원하는 오픈소스 이기 때문에 현재 Hadoop과 더불어 가장 인기있는 키워드 중에 하나가 되었다. 학부과정과 석사 과정중에 생명정보학에 대해서 수업을 할 때 유전자의 alignment를 분석하고 리포팅하기 위해서 R을 사용한적이 있는데, 실제 C나 Java로 작성하면 엄청나게 하드 코딩해야할 것을 R로 간단하게 분석 통계를 만들고 리포팅할 수 있다는 것을 경험한 적이 있다. 이러한 R 이 이젠 실제 업무에서 가장 중요한 프로그래밍 언어로 자리잡고 있다. 마지막으로 오픈소스에 대한 잘못된 이해에 대해서 잠시 커멘트를 해주면서 세션을 마쳤는데 공감가는 내용을 말씀해주셨다. 기업들은 오픈 소스라고 하면 모두 Free로 생각하는데 이것은 잘못된 견해이다. 오픈 소스는 사용료의 무료 개념이 아니라 공유가 기본 개념이라는 것이다. 그리고 오픈 소스는 이전까지의 기업에서 해오던 개발 방법과 환경과 매우 다르기 때문에 오픈소스 전문가가 반드시 필요하다는 것이다. 이번 세션들 모두에서 발표자들이 하는 말이 오픈소스가 무료소스라는 생각을 바꿔야한다고 이야기할 정도로 현재의 기업의 오픈소스 인식이 잘못된 것 같다.
오픈소스를 활용한 Big Data 구축 동향
다음은 “오픈소스를 활용한 Big Data 구축 동향”이라는 주제로 NexR의 데이터분석팀 PM 김영우(@youngwookim)님께서 발표를 했다. Hadoop에 대해서 소개해주면서 시스템을 구축할때 참고해야할 Hadoop의 안정화 버전, 버저닝의 의미에 대해서 자세히 소개했다.. 뿐만아니라 여깃 Hive에 대해서 왜 NexR에서 Hive를 도입할 수 밖에 없었는지에 대해서도 소개했다.
발표자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_OSSBi


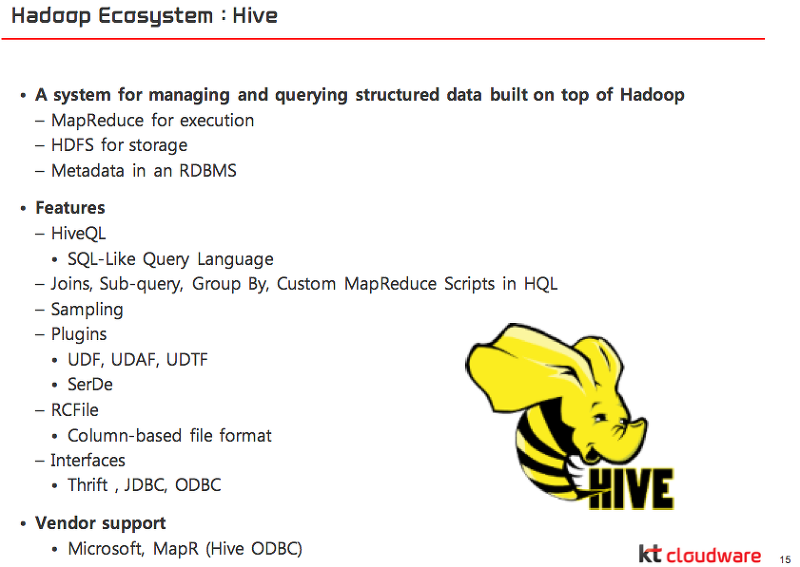
뿐만 아니라 Hadoop의 Echosystem에 대해서 오픈소를 활용할 수 있는 예들을 계속해서 발표해주셨다. 또한, Big와 Hive에 대해서도 간단히 비교했다. 두가지 모두 Map Reduce를 프로그래밍이 아닌 간단한 인터페에스를 사용하는데 Pig는 pig script를 사용하고 Hive는 SQL을 사용할 수 있다는 비교를 아래 자료에서 확인할 수 이다.
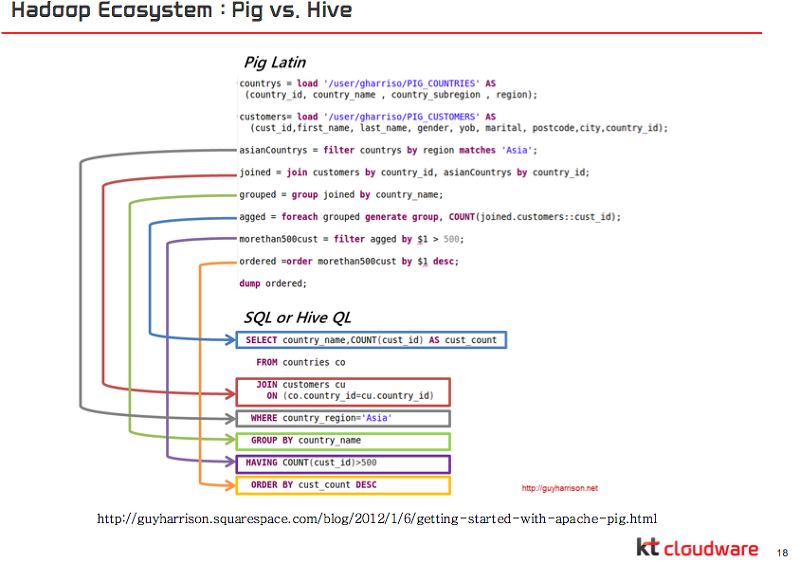
이미 Hadoop는 enterprise 급에 사용하기에 전혀 문제되지 않을 만큰 안정화되어서 릴리즈되어 있는 상태라고 말했고, 현재 존재하는 big data 처리에서 Hadoop은 빠질 수 없는 부분이라고 말했다.
Open Source Software Directions in Cloud Computing
다음 세션은 KT Cloud를 구축할때 컨설트를 담당했던 아키텍터인 James Clark이 “Open Source Software Directions in Cloud Computing”라는 주제로 발표를 진행하였다. 오픈소스와 클라우드에 대해서 이야기를 해주었는데, 역시나 무료 컨퍼런스라서 동시통역이 없었다는 것이 조금 아쉬웠다. 아마 동시 통역이 없는 이유로 발표내용을 전부 이해하진 못한듯 하다. 하지만 몇몇 슬라이드에서는 정말 궁금하던 내용을 간단 명료하게 정의해주고 발표해주었다.
발표자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_osspres_James%20Clark.pdf

각 세션마다 오픈소스라는 주제에 대해서 한다미씩 하였는데 Clark 다음과 같이 발표하였다.

또한 클라우드에해서도 아주 명확하게 말했는데 최근에 들은 클라우드에 대한 정의중 가장 깔끔하지 않았나 생각이 들었었다.


다음 세션은 패널 토의가 진행되었다. 사회는 한재선 님께서 해주시고 패널은 김영우, 김재홍, 전희원 님이였는데, 생각보다 참여자들의 질문이 없어서 한재선님이 주최측에서 준비한 질문을 공개적으로 답변하는 시간이 진행되었다. 나는 이제 처음 빅데이터와 클라우드에 대해서 연구를 시작하려는 연구원이라서 실제 운영중에 궁금한 점을 몰라서 질문하지 못했는데, 개인적으로 다른 참여자들의 질문이 없어서 좀 아쉽긴했다. 하지만 미리 준비된 내용이 꽤 괜찮고 생각해볼만한 주제라서 유익한 답변을 많이 들을 수 있었다. 특히, 라이센스 문제는 경험해보지 못한 문제였는데, 라이센스 문제가 오픈소스로 서비스를 구축하면 생기는 큰 문제중에 하나라는 것을 알게되었다. LGPL 라이센스의 코드 공개부분과 LGPL을 사용하기 부담스러워하는 기업의 반응, Apache 라이센스가 적용되면 더 많은 개발자와 벤더들이 사용할 수 있다는 것 등을 알게되었다. 또한 LGPL이라고 반드시 코드를 모두 공개해야하는 것이 아니라는 것도 알 수 있었다. 이쪽 분야에 대해서 해박한 지식이 없어서 그런지 Xen에 대해서도 처음 듣게 되었다. 패널 토의가 끝날무렵 한재선님께서 요즘 개발자들이 빅데이터에 대해서 와주 관심은 많지만 실제 빅데이터를 한번이라도 제대로 테스트하거나 운영한 사람은 찾기 어렵다고 정확한 지적도 해주었다.

Open Source를 활용한 통신사 Big Data System 구축 사례
점심 식사 이후로 NexR의 데이터분석플랫폼 PM 정구범 (@mypowerbox) 님께서 “Open Source를 활용한 통신사 Big Data System 구축 사례”에 대해서 발표를 진행했다.
Hadoop등 오픈소스로 기존의 Oracle 기반의 DW에 적용한 사례에 대해서 발표를 진행하였는데, Oracle로 구현되었던 DW보다 Hadoop 기반으로 노드를 확장해서 처리해서 더 좋은 성능을 절감했다는 내용 상세히 설명을 해주었다.
발표자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_Telco%20Big%20Data%20System_jkb.pdf
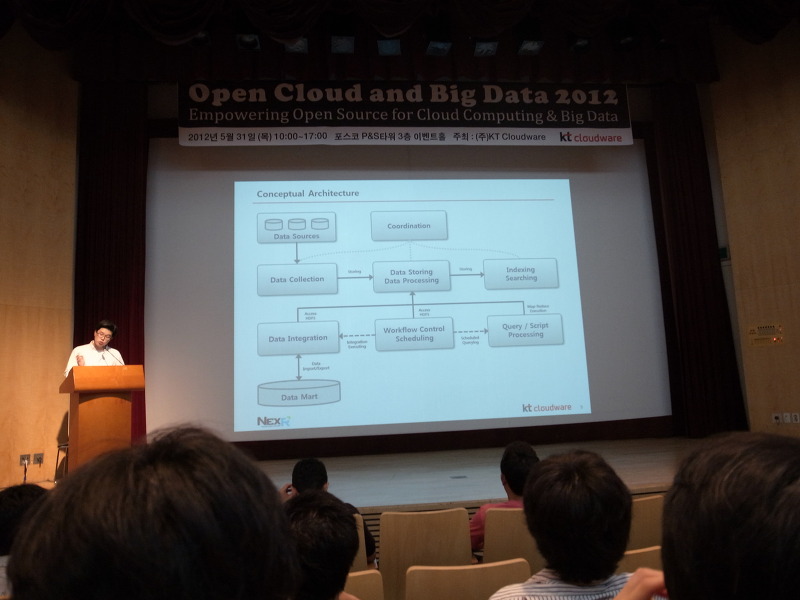
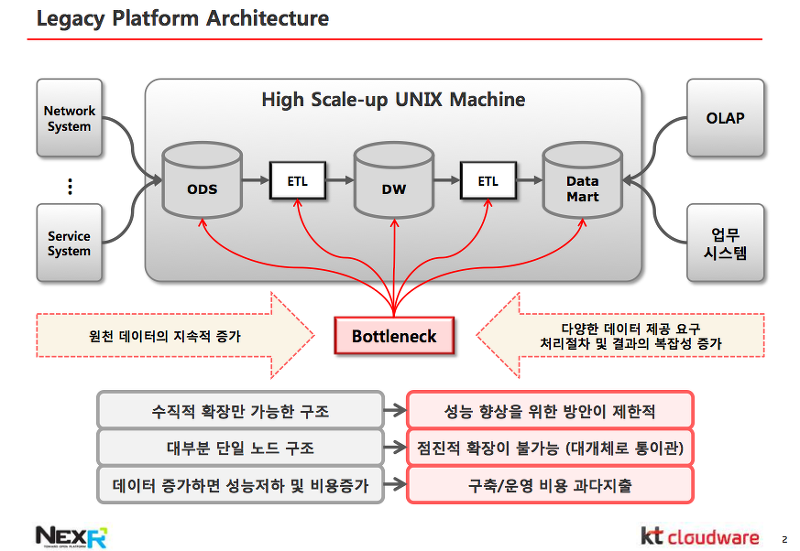
아래는 기존의 플랫폼 아키텍처에 대한 간단한 설명과 문제점에 대해서 나타난 슬라이드이다.
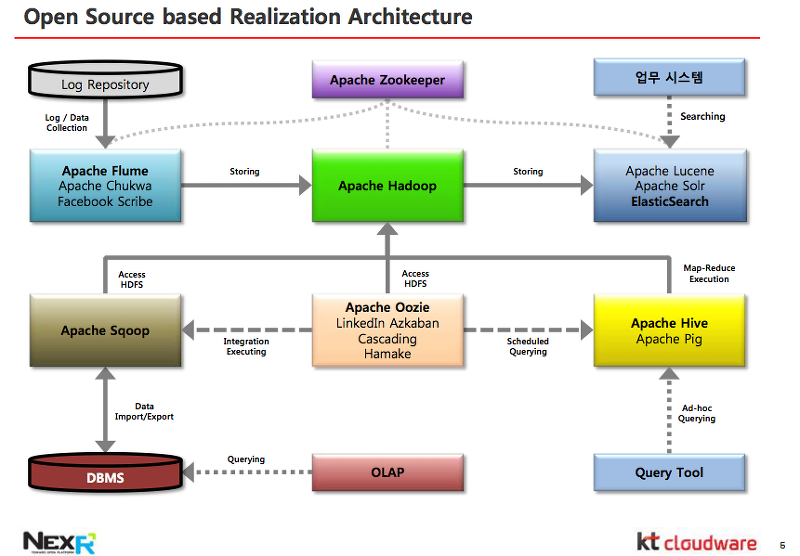
아래는 Open Source 기반으로 구성한 아키텍처를 설명한 슬리이드이다.
고급 분석의 신흥강자 R과 Big Data Analysis
다음 세션은 NexR의 데이터분석팀 권정민 수석연구원께서 “고급 분석의 신흥강자 R과 Big Data Analysis”라는 주제로 발표를 진행했다. 이 세션에서는 R에 대해서 좀더 자세하게 설명을 해주었는데, 학부과정과 석사과정에 생명정보학 연구에 사용했던 R의 사용법과 기능을들이 새롭게 정리되는 시간이였다. 실제 R에서는 수학적 알고리즘이나 함수들이 이미 많은 라이브러리고 구현이 되어 있는 상태이기 때문에 개발자들이 수학적 모델을 프로그래밍하는 시간을 많이 줄일 수 있어서 좋다. 또한 오픈소스 커뮤니티가 활발한 편이라서 서드파티 라이브러리들이 많이 개발되고 있기도한다. 빅데이터의 이슈는 결국 데이터를 어떻게 잘 분석하는가에 따라서 기대효과를 볼 수 있는데 이러한 이유에서 빅데이터에서 분석 툴의 선택은 배우 중요한 요가 될 것이다. 이런 의미에서 R는 기존의 SPSS 와 같은 소프트웨어랑 다르다고 볼 수 있다. R은 그 자체가 툴이면서 분석 프로그램을 할 수 있는 환경을 제공해주고 외부 프로그램들과 상호연동을 잘 할 수 있는 오픈소스이기 때문이다.
발표자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_R_Big%20Dat

OpenStack과 CloudStack
다음은 OpenStack과 CloudStack 에대한 세션들이 진행되었다. OpenStack은 KT 클라우드 OS 개발팀 안재석 팀장님이 발표했고, CloudStack는 서상원 KT Cloudware 본부장님이 발표를 진행했다.
OpenStack에 관한 발표자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_openStack_ajs.pdf CloudStack에 관한 발표자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_cloudstack_towards_open_ssw.pdf

CloudStack은 GPL 라이센스에서 Aapache 라이센스로 변경되면서 더욱 빠르게 성장하고 참여가 높아 지고 있다고 한다.


마지막 세션은 KT Cloudware의 서버가상화팀 김재홍 팀장께서 발표를 해주셨는데, uCloud를 구축할때 Open Source를 활용한 사례를 발표해주었다.
발표자료 : http://opensource.ktcloudware.com/opensource/files/OpenCloud2012_Cloud%20Computing_kjh.pdf

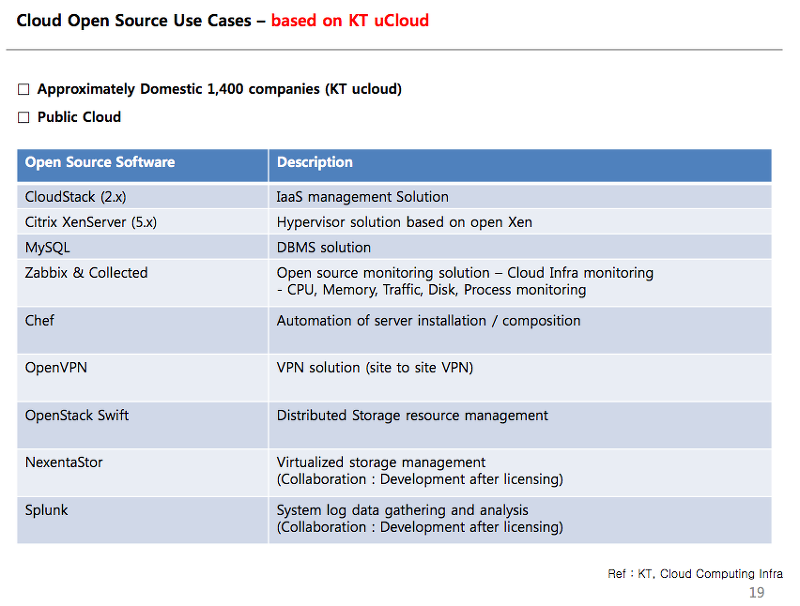
학교 연구실, 연구소에서 Big Data에 대해서 실제로 서비스할 곳이 그렇게 많지가 않지만 연구분야의 주제로 어떻게 시작해야할지, 어떤 오픈 소스를 사용해야할지에 대해서 뜬 구름 같은 생각이 들었는데 이번 컨퍼런스를 다녀오고 난 이후 그 방향이 약간은 잡히는 것 같았다. 특히 오픈소스로 아키텍처를 구축한 사례, 어떤 오픈소스들을 사용했는지에 대한 사례 처음 빅데이터와 클라우드 구축을 하려는 우리 같은 연구소에게는 매우 고마운 발표와 자료가 아니었나 생각이 든다. 아직 가상화와 클라우드에 대한 시스템 구축을 한번도 해보지 않았지만, 이날 발표자들이 말하기를 오픈소스로 에코시스템을 구축한다는 것은 아주 많은 커스터마이징 작업을 해야한다는 것이였다. 이러한 이유로 클라우드나 빅 데이터에 대한 관심들은 너무나들 많으나 실제 시스템을 구축하고 운영할줄 아는 전문가들이 부족하다는 것이다. 그래서 이번 컨퍼런스 자료 내용으로 실험용 클라우드와 빅데이터 시스템을 구축해볼 예정이다. 현재 진행중인 프로젝트가 끝나면 이 연구주제에 대해서 블로그에 포스팅하면서 공유하고 싶다. 하루의 짦은 시간이지만 이렇게 서울에 올라와서 이런 자료를 얻고, 발표내용을 들으면서 생각하지 못하고 찾지못한 방법을 얻게되어서 다행이다. 서울에서 흔한 교육이라도 왕복 6시간 넘게 새벽같이 일어나서 어렵게 참석하지만 이렇게 얻고 가는 교육들은 참 기분이 좋다. 늘 느끼는 것이지만 클라우드와 빅데이터 분야에서는 NexR의 발표가 가장 좋은것 같다. 다음에 Big Data 컨퍼런스를 또 준비하고 있다고 하던데 그 컨프런스에 다시 참석해서 좀더 디테일한 설명과 자료를 얻어가고 싶다고 생각하면서 마무리하고 내려왔다.
좋은 컨퍼런스에 참석할 수 있게 지원해주신 교수님과 연구소에 감사드립니다.
연구원 소개
- 작성자 : 송성광 개발 연구원
- 블로그 : http://blog.saltfactory.net
- 이메일 : saltfactory@gmail.com
- 트위터 : @saltfactory
- 페이스북 : https://facebook.com/salthub
- 연구소 : 하이브레인넷 부설연구소
- 연구실 : 창원대학교 데이터베이스 연구실