Node.js를 이용하여 웹 사이트 데이터 가져오기(web scraping, Phantomjs)
서론
우리는 흔히 데이터를 데이터베이스에서 가져온다고 생각한다. 실제 웹사이트를 구축할 때 웹 페이지를 생성하기 위해서 웹 프로그램이 데이터베이스에서 데이터를 조회해서 웹 페이지를 만드는데 요즘은 API 서비스들이 많기 때문에 데이터를 가져오는 것이 데이터베이스에만 국한되지 않고 API를 통해서 가져오기도 한다. 하지만 API를 지원하지 않는 서비스에서 데이터를 가져오는 방법은 없을까? 고민하게 되는 경우도 있다. 예를 들어서, 석사때 학교 기숙사에 지내면서 기숙사 게시판의 공지를 매번 사이트에 들어가서 확인하는 것이 불편하고 또 중요한 공지사항이 있음에도 불구하고 시간이 없어서 웹 사이트를 방문하지 않아서 공지를 놓치는 경우가 많았었다. 그래서 ruby로 웹 사이트의 HTML 코드를 가져와서 분석해서 새로운 공지가 있을 때 알람을 주는 프로그램을 만든 적이 있다. 이런 것을 웹사이트 긁어오기(web scraping)라는 말을 한다. HTML에 발전하면서 XHTML 부터 이젠 HTML도 validation을 지켜야하기 때문에 HTML5 발전이 되면서 최근에는 웹 사이트의 HTML들이 매우 정형화되어 있기 때문에 마치 XML을 분석하듯이 웹사이트를 잘 구조화된 일종의 데이터베이스로 생각해도 된다. 오늘 포스팅은 웹사이트를 분석해서 필요한 데이터를 가져오는 방법을 간단히 소개한다.
Ruby로 웹 사이트 데이터 가져오기
첫번째로 이전에 웹 사이트의 데이터를 어떻게 가져왔는지 간단한 예제를 소개한다. Ruby는 웹 사이트를 open-uri를 이용해서 가져올 수 있고, nokogiri를 이용해서 XML의 XPATH와 같이 HTML 코드를 탐색할 수 있다. 필요한 모듈을 gem을 설치한다.
gem install open-uri --no-rdoc
gem install nokogiri --no-rdoc
이젠 웹사이트에서 HTML을 가져올 준비를 마쳤다. 다음과 같이 사이트에서 HTML 코드를 가져오자. 예제로 이 블로그를 테스트한다.
# filename : scraping.rb
# author : saltfactory@gmail.com
require "nokogiri"
require "open-uri"
html = Nokogiri::HTML(open("http://blog.saltfactory.net"))
puts html
ruby를 실행한다.
ruby scraping.rb
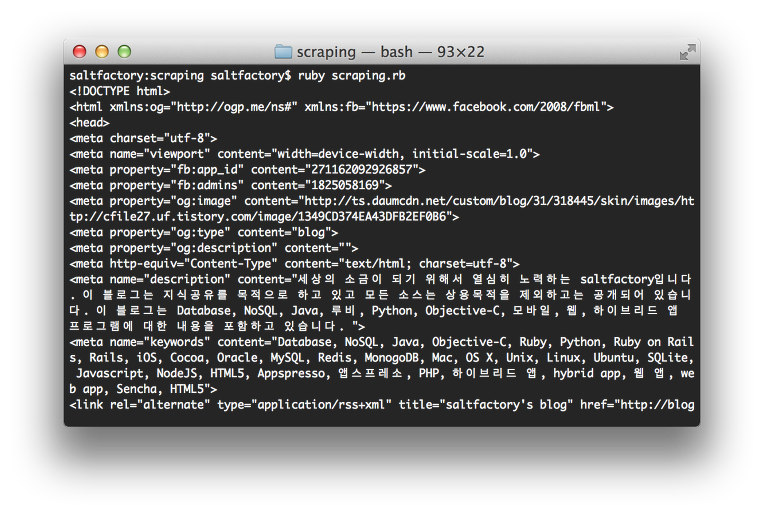
위와 같이 ruby로 웹 사이트의 HTML 페이지 코드를 모두 가져온 것을 확인할 수 있다. 이젠 이 코드에서 필요한 데이터를 가져오자. 이 블로그는 Daum에서 운영하는 Tistory 블로그이다. Tistory 블로그에서는 방문자 수를 보여주는데 오늘 몇명이 블로그에 방문했는지를 확인하기 위해서 매번 웹 사이트를 방문하기 불편하기 때문에 오늘 방문자 수를 웹 사이트를 열지 않고 가져오는 방법을 예를 들겠다.
Tistory에서는 웹 사이트 방문자를 <li id="side_today_count"> 방문자 수</li> 로 HTML 코드에서 만들어서 보여주고 있다. 그래서 nokogiri를 이용해서 데이터를 가져도록 한다. nokogiri는 XML의 XPATH를 지원한다. XPATH의 사용법은 다음을 참고하자. http://www.w3schools.com/xpath/
# filename : scraping.rb
# author : saltfactory@gmail.com
require "nokogiri"
require "open-uri"
html = Nokogiri::HTML(open("http://blog.saltfactory.net"))
#puts html
side_today_count = html.xpath("//li[@id='side_today_count']").text
puts "오늘의 방문자 수 : #{side_today_count}"
ruby를 실행하면 다음과 같이 오늘 방문자를 확인할 수 있다. 지금은 오전이라 방문자 수가 적다.
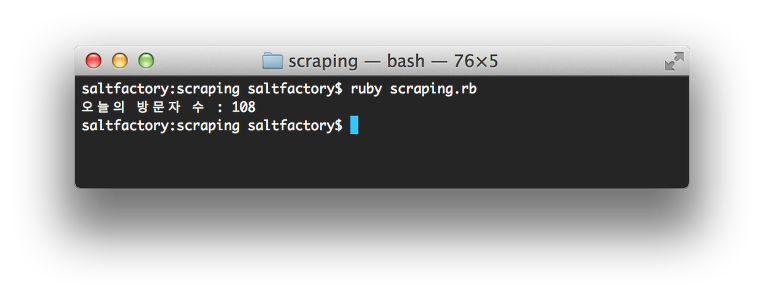
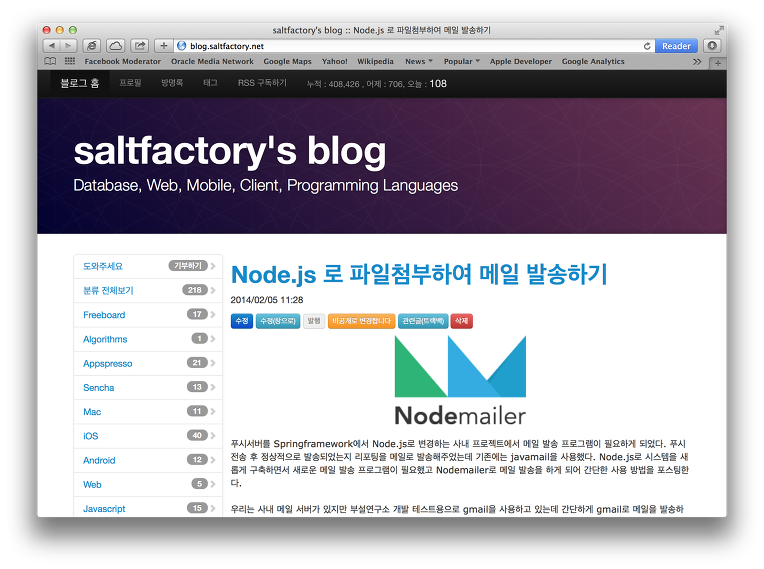
실제 방문자 수가 같은지 웹 사이트를 확인해보자. 웹 사이트의 방문자 수를 확인하면 위의 결과와 동일하다는 것을 확인할 수 있다.
Node.js 로 웹 사이트 데이터 가져오기
이젠 Node.js로 웹 사이트의 데이터를 가져오는 방법을 알아보자. 원리는 동일하다. HTML 코드를 가져와서 파싱해서 필요한 데이터를 가져오는데 ruby에서 open-uri와 같은 일을 request로 할 수 있고 nokogiri와 같은 일을 cheerio로 할 수 있다. 먼저 request와 cheerio 모듈을 npm으로 설치한다.
npm install request
npm install cheerio
Node.js 모듈을 설치가 완료되면 다음과 같이 코드를 작성한다.
// filename : scraping.js
// author : saltfactory@gmail.com
var cheerio = require('cheerio');
var request = require('request');
var url = 'http://blog.saltfactory.net';
request(url, function(error, response, html){
if (error) {throw error};
console.log (html);
});
node로 실행을 한다.
node scraping.js
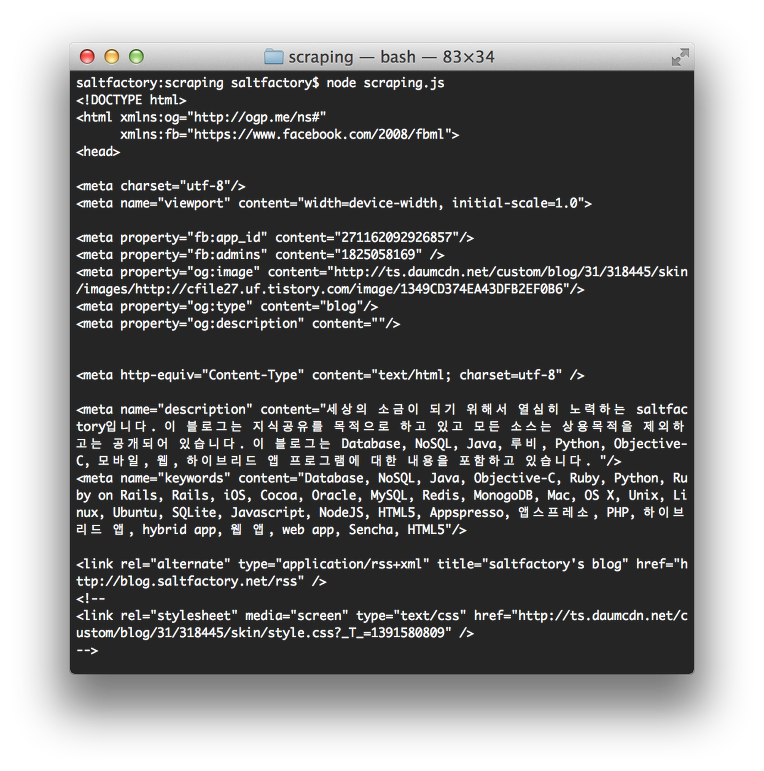
실행한 결과는 위에 ruby로 작성한 것과 동일하게 HTML 코드를 가져오는 것을 확인할 수 있다. 다음은 nokogiri의 XPATH를 사용하여 데이터를 가져온 것 처럼 cheerio를 이용해서 마치 jQuery 처럼 데이터를 가져게 해보자.
// filename : scraping.js
// author : saltfactory@gmail.com
var cheerio = require('cheerio');
var request = require('request');
var url = 'http://blog.saltfactory.net';
request(url, function(error, response, html){
if (error) {throw error};
// console.log (html);
var $ = cheerio.load(html);
$('#side_today_count').each(function(){
console.log("오늘의 방문자 수 : " + $(this).text());
})
});
실행하면 우리가 원하는 데이터를 웹사이트에서 가져올 수 있는 것을 확인 할 수 있다. 글을 작성하는 시간에도 방문자들 있어서 방문자 수가 늘었다.

Phantomjs로 웹사이트 데이터 가져오기
위의 두가지 방법은 웹사이트를 HTTP client를 이용해서 웹 사이트의 HTML을 가져와서 가져온 데이터를 파싱하는 모듈로 데이터를 가져왔는데, 만약에 웹 브라우저가 가상으로 동작해서 데이터를 가져오면 어떨까? 그럼 가상 웹 브라우저는 있을까? 생각할 수 있다. 이런 궁금증을 Phantomjs에서 해답을 찾을 수 있다. Phantomjs는 healess webkit 으로 브라우저는 없지만 브라우저와 동일하게 동작을 한다. 자세한 내용은 http://phantomjs.org 에서 확인하자.
우선 phantomjs를 설치해야하는데 Homebrew를 이용해서 간단하게 설치할 수 있다. Homebrew에 대한 사용방법은 다음 글을 참조한다. http://blog.saltfactory.net/109
brew install phantomjs
Phantomjs에서 웹 사이트를 여는 방법은 다음과 같다.
// filename : scraping_phantom.js
// author : saltfactory@gmail.com
var page = require('webpage').create();
page.open('http://blog.saltfactory.net', function (status) {
if (status) {
var html = page.content;
console.log(html);
};
phantom.exit();
});
이제 phantomjs를 실행한다.
phantomjs scraping_phantom.js

Phantomjs의 실행 결과는 위의 코드들과 동일하다는 것을 확인할 수 있다. 이젠 Phantomjs에서 필요한 데이터를 가져와보자. phantomjs는 webkit 엔진을 wrapping하고 있기 때문에 HTML의 DOM API를 바로 사용할 수 있다. 그래서 document.getElementById로 필요한 데이터에 바로 접근할 수 있다.
// filename : scraping_phantom.js
// author : saltfactory@gmail.com
var page = require('webpage').create();
page.open('http://blog.saltfactory.net', function (status) {
if (status) {
var html = page.content;
// console.log(html);
var side_today_count = page.evaluate(function(){
return document.getElementById('side_today_count').textContent;
});
console.log("오늘의 방문자 수 : " + side_today_count);
};
phantom.exit();
});
다시 phantomjs를 실행한다. 결과가 동일하게 나오는 것을 확인할 수 있다.

Phantomjs를 node에서 사용하기
Phantomjs를 node에서 사용하기 위해서는, 다시 말해서 node의 module로 사용하기 위해서는 phantom 모듈을 npm으로 설치해야한다.
npm install phantom
그리고 위의 코드를 다음과 같이 변경한다.
// filename : scraping_phantom.js
// author : saltfactory@gmail.com
var phantom = require('phantom');
phantom.create(function(ph) {
return ph.createPage(function(page) {
return page.open("http://blog.saltfactory.net", function(status) {
return page.evaluate((function() {
return document.getElementById('side_today_count').textContent;
}), function(side_today_count) {
console.log("오늘의 방문자 수 : " + side_today_count);
return ph.exit();
});
});
});
});
이제 node 모듈 phatom을 사용한 위 코드를 node로 실행한다.
node scraping_phantom.js

결론
우리는 로컬 데이터베이스나 오픈 API를 이용해서 데이터를 획득해서 웹 서비스나 다양한 어플리케이션을 만들 수 있다. 하지만 때로는 우리가 데이터를 웹 사이트에서 가져와야하는 경우가 있는데 최근 HTML의 발전으로 HTML이 정형화 되었기 때문에 웹 사이트에서 HTML을 문석해서 데이터를 가져올 수 있게 되었다. HTML이 잘 구조화 되지 않으면 HTML 파싱이나 DOM 접근이 불가능할 수 있지만 최근에는 HTML 코드 validation을 지키고 있기 때문에 HTML 코드에서 데이터를 가져오는 것이 대부분 가능하다. 아직 validation 을 지키지 않는 개발자가 만든 웹 사이트가 아니면 말이다. 이렇게 웹 사이트 자체가 마치 하나의 정형화된 문서로 만들어지기 때문에 우리는 웹 사이트를 마치 데이터베이스처럼 사용할 수 있다. 여러가지 언어로 웹 사이트 데이터 가져오기는 가능하다. 이 포스팅에서는 Ruby와 Nodejs 그리고 phantomjs를 사용하는 예제를 소개했다. ruby는 gem을 이용해서 open-uri, nokogiri를 이용해서 가능하고 Nodejs는 request, cheerio를 이용해서 간단하게 HTML을 파싱할 수 있다. 또한, Phantomjs를 이용해서 headless webkit이라는 엔진을 사용해 웹 사이트를 접근할 수 있다는 것도 살펴보았다. Phantomjs는 위의 소개된 내용 말고도 다양한 장점이 있다. Phantomjs의 유용한 사용법에 대해서는 다음 포스팅에 좀 더 자세하게 소개하려고 한다. 개발자들은 사용자의 편리함을 창조하기도 하지만, 개발자들의 프로그래밍 편리함도 창조하고 있다. 브라우저 없이 웹사이트에 접근해서 필요한 데이터를 가져온다는 것은 정말 흥미롭고 재밌는 일이기 때문이다. 여담이지만, 기숙사 생활을 하면서 ruby로 web scraping 프로그램을 만들어서 새로운 공지사항이 있을 때 알림을 알려주는 기능은 꽤 유용했고 편리하게 기숙사 생활을 할 수 있었던 기억이 있다. 개발자라면 단순한 반복 작업을 간단한 프로그램으로 단순한 작업을 하지 않게 할 수 있어야한다는 생각이다. 즐거운 연구와 개발을 할 수 있는데 도움이 되기 바란다.
참고
- http://blog.miguelgrinberg.com/post/easy-web-scraping-with-nodejs
- https://github.com/MatthewMueller/cheerio
- http://code.tutsplus.com/tutorials/web-scraping-with-node-js–net-25560
- http://phantomjs.org/page-automation.html
- http://nodeqa.com/nodejs_ref/40
연구원 소개
- 작성자 : 송성광 개발 연구원
- 블로그 : http://blog.saltfactory.net
- 이메일 : saltfactory@gmail.com
- 트위터 : @saltfactory
- 페이스북 : https://facebook.com/salthub
- 연구소 : 하이브레인넷 부설연구소
- 연구실 : 창원대학교 데이터베이스 연구실