We’ve shipped 25 updates to GitHub for Windows in the 4 months since we first launched. That’s more than one release per week, for 17 weeks straight! Here’s how we do it.
One release per week — for a desktop app?!
At GitHub, we ship a lot. We think it’s so important to ship often, we even have a shipping mascot and matching emoji ( ). Why do we do this?
). Why do we do this?
Shipping rapidly is important to us for so many reasons. For example, the more frequently we ship the less likely it is for large numbers of changes to build up between releases, and shipping a small release is almost always less risky than shipping a big one. Shipping frequently also requires that we make it downright simple to ship by automating it, so anyone can do it. This raises our bus factor, and also democratizes the process of shipping so there aren’t “gatekeepers” who must sign off before any software goes out the door. And by shipping updates so often, there is less anxiety about getting a particular feature ready for a particular release. If your pull request isn’t ready to be merged in time for today’s release, relax. There will be another one soon, so make that code shine!
We really take this to heart. GitHub.com gets deployed hundreds of times each day. But we don’t think shipping often should be limited to web apps. We want all these same benefits for our native apps, too!
Let’s see how we’ve been doing with GitHub for Windows.
Some numbers
I said above that we’ve shipped 25 updates in 4 months. That comes out to about one release every 5 days, on average, and the median time between releases is only half that, 2.5 days. A full 75% of our updates so far shipped in less than 7 days.
The story is largely the same if you look at releases in terms of the number of commits that went into each release. We’ve made 1,176 commits on our master branch since our first release. That's 47 commits per release on average, with a median of 41 commits per release. 72% of GitHub for Windows updates so far have contained fewer than 50 commits.
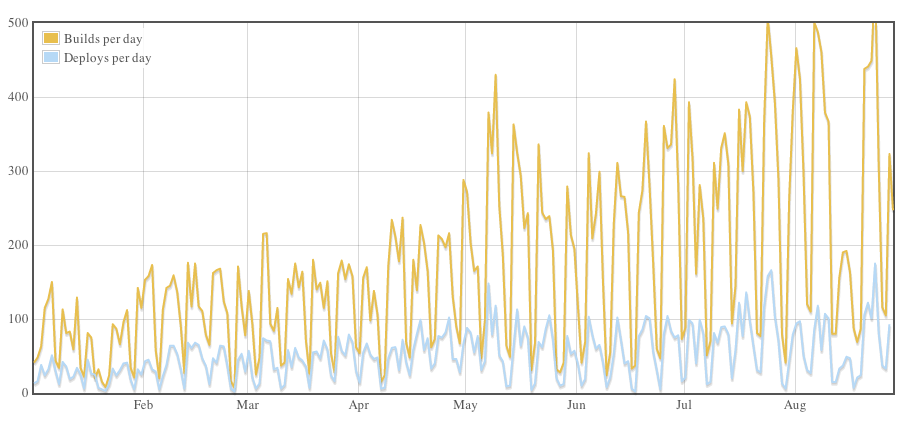
Here’s a graph that shows all of our updates to GitHub for Windows thus far, with days since the previous release on the X axis and commits since the previous release on the Y axis:

That cluster of releases down in the bottom-left corner near the origin is exactly what we want. We work hard to make our updates as small as possible and to release them quickly, and I think the numbers bear that out.
So, how do we do it?
Automate everything (for us)
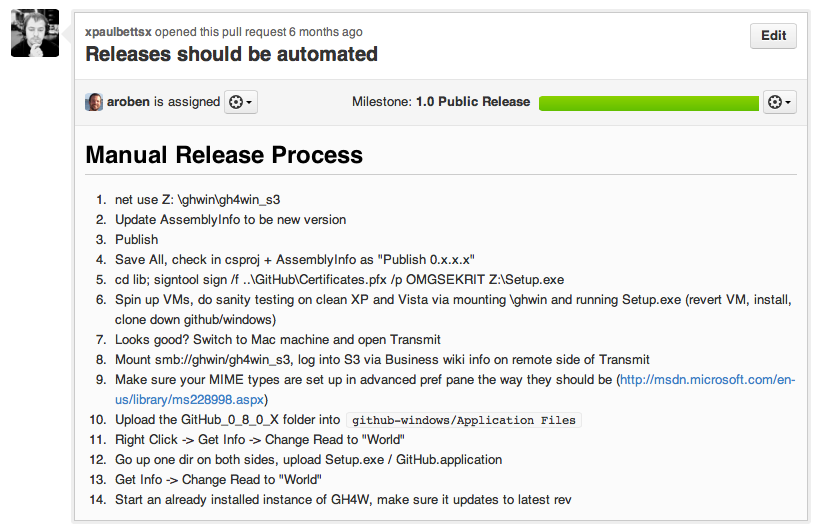
As I said earlier, shipping often requires that shipping be automated. When I joined GitHub back in March, shipping GitHub for Windows to our private beta group was a completely manual process, and Paul was the only one who knew how to do it. In fact, Paul was away my first week, so we weren’t able to ship an update we had all ready to go!
So Paul opened this issue in our GitHub for Windows repository:

Even now, looking at that release process makes me cry.
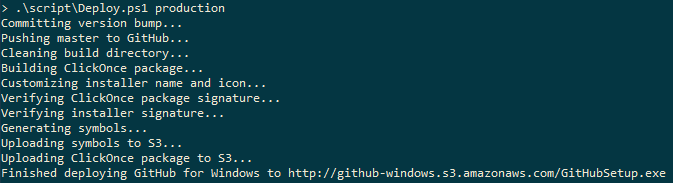
I, the bright-eyed, bushy-tailed newbie, got to work automating the process. Here’s how we deploy a release now:

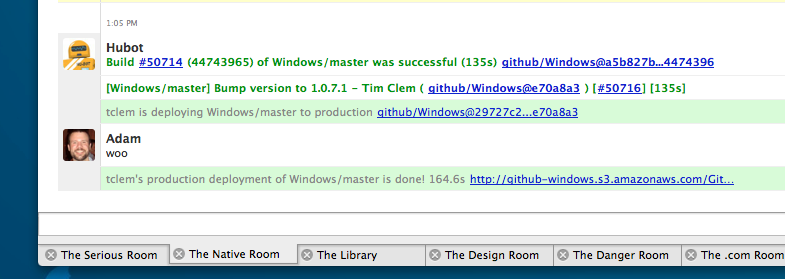
One command, .\script\Deploy.ps1 production, is all it takes to build, package, and deploy a new GitHub for Windows release. We can also deploy just to GitHub staff, which we do for testing changes before releasing them to the public, by running .\script\Deploy.ps1 staff. Lowering the barrier to shipping means that anyone can ship an update, not just Paul, and that we can do it frequently, even multiple times a day.
As Deploy.ps1 runs, it posts status to one of our Campfire chat rooms. This lets the rest of the team see what’s going on, saves a record of the deploy in Campfire’s logs for posterity, and lets us cheer each other on.

In addition to deploying our installer, Deploy.ps1 uploads debug symbols (PDB files) for each release to our symbol server, a custom proxy backed by Amazon S3. This makes it possible to debug crash dumps from users. We even have some other PowerShell scripts to automate that so you don’t have to be a crash dump expert just to see what went wrong.
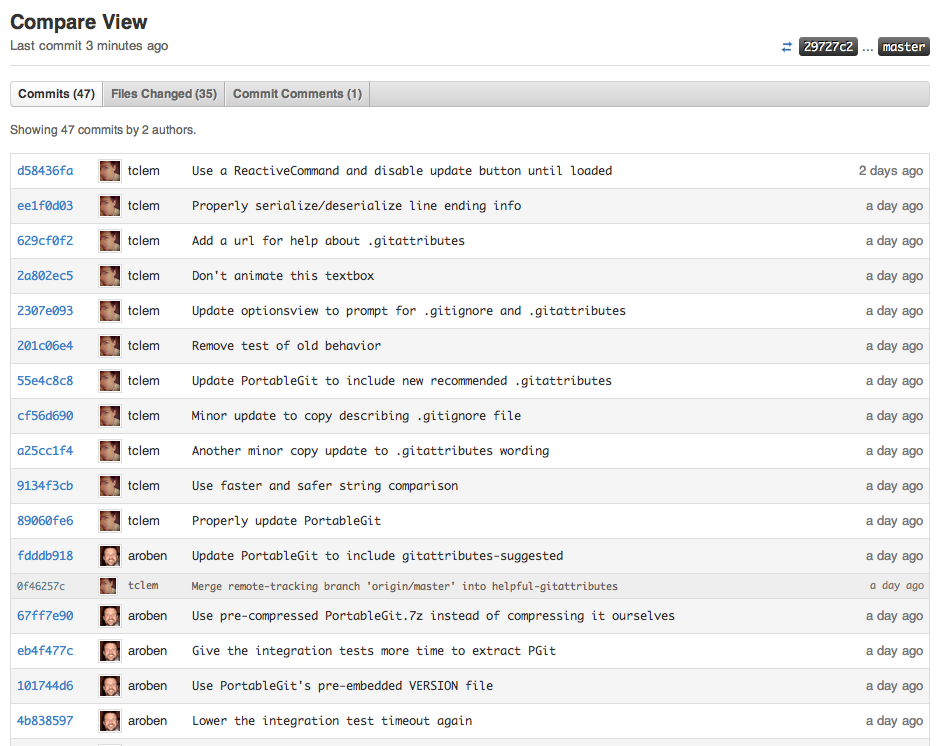
Every release contains a change log that details the most important fixes and improvements contained in that release. The change log is stored in a JSON file in the GitHub for Windows repository, and uploaded to S3 with each deploy. GitHub for Windows downloads the change log from S3 to show you what’s new in the update it’s about to install, and http://windows.github.com/ uses it to show release notes from all our past versions. When we decide it’s time to make a new release, we just ask Hubot what’s changed since our last release:

Hubot provides a link to a compare view on GitHub.com that shows exactly what commits and pull requests haven’t yet been deployed, making writing a change log a breeze.

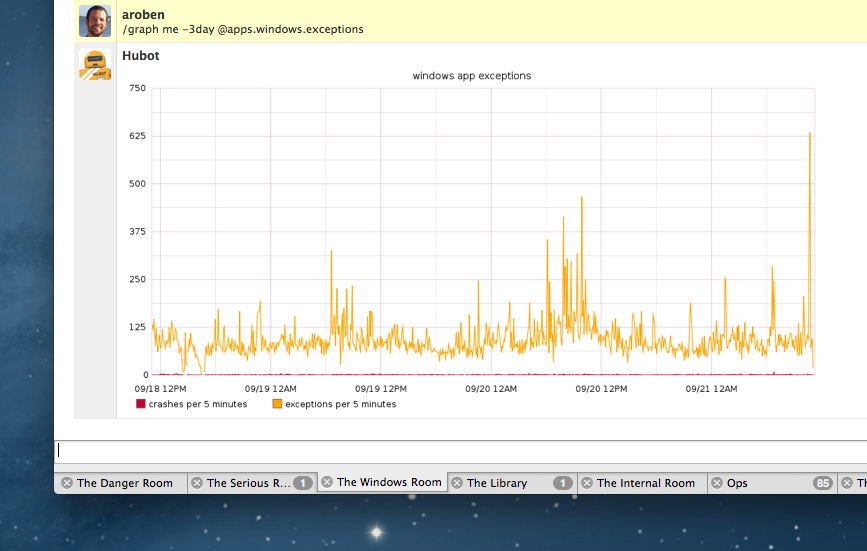
We also use Hubot to monitor releases after we ship them. For instance, whenever GitHub for Windows throws an exception or crashes, it sends information about the exception or crash to Haystack, our internal exception aggregation app. We can ask Hubot to show us data from Haystack to determine how many exceptions and crashes our users are seeing, which is particularly useful just after an update has been released:

If we find that exceptions or crashes are increasing, we can go to Haystack to find out what’s going wrong.
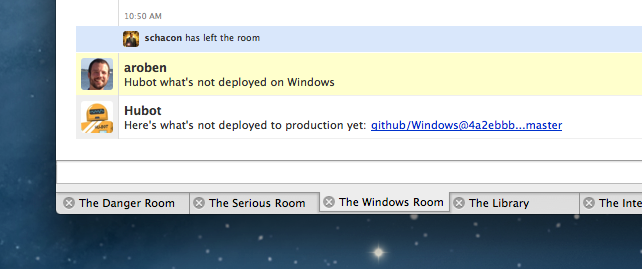
We can even use Hubot to get an idea of how quickly users are updating to the latest version. Speaking of which…
Automate everything (for you)
Shipping so often would be for naught if our users weren’t actually installing our updates. So we’ve made downloading and installing updates to GitHub for Windows completely automated, too. GitHub for Windows checks for updates periodically, and when it finds one, it installs it in the background. The next time you relaunch the app, you’re automatically running the latest and greatest version, hot off our servers.
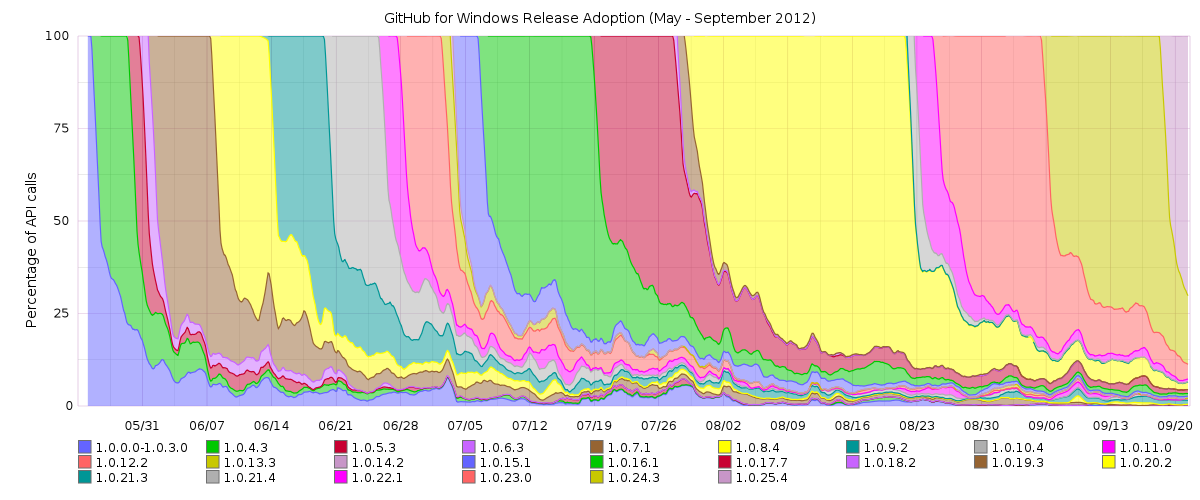
This results in our updates getting adopted by users remarkably quickly. Here’s a graph of all the GitHub for Windows releases we’ve made. On the X axis is time. On the Y axis is the percentage of total API calls to GitHub.com that are being made by each version of GitHub for Windows, stacked.

For example, on July 26th you can see that around 70% of API calls were coming from version 1.0.17.7, an additional 10% were coming from version 1.0.16.1, and older versions made up the remaining 20%.
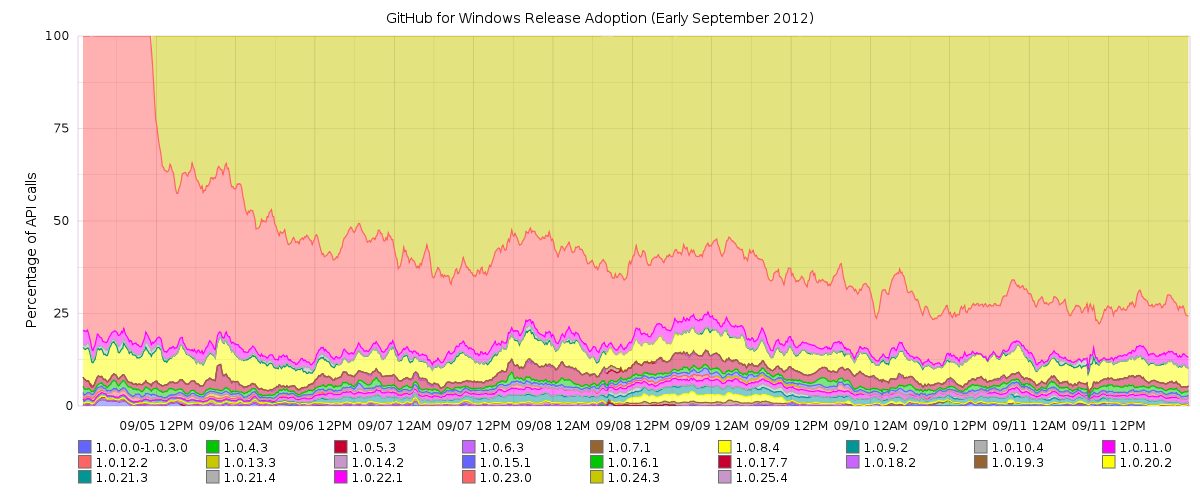
The steep line when each release first appears gives you a good idea of how quickly releases start being used. But to really see just how quickly updates make it onto users’ machines, let’s zoom in on one week in early September, when we shipped our 1.0.24.3 update:

Within an hour, 25% of API calls were coming from the version we had just deployed. In 18 hours, it was over 50%. Within a week, it was over 70%.
This is really incredible. Even Google Chrome, which in many ways pioneered smooth, automatic updates for desktop software, only sees about 33% adoption in the first week after an update. By making the update process so smooth, we’re able to get bug fixes and new features into the hands of users just hours after deploying. Our users seem to like it, too; in 4 months we’ve gained over 125,000 users, and there’s no sign of it slowing down yet:

We’re not done yet
It makes me incredibly happy to be able to ship GitHub for Windows so often and get it in users’ hands so quickly. But there’s still more to do. We’re always thinking about ways to make the download size of updates even smaller to help users on slow connections, and to make updates more reliable for users behind proxies. We want to make deploying even easier and more consistent with our other products by integrating with our Heaven Sinatra app. And we want to remove the few remaining manual steps to further reduce the chance of mistakes and to encourage shipping more often.
The more quickly and easily we can ship, the better GitHub for Windows will be, the happier we will be, and the happier our users will be.


















{kind=link}
{kind=link}
{kind=link}