GitHub.com no longer delivers its icons via icon font. Instead, we’ve replaced all the Octicons throughout our codebase with SVG alternatives. While the changes are mostly under-the-hood, you’ll immediately feel the benefits of the SVG icons.
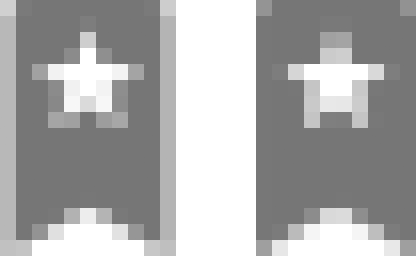
Switching to SVG renders our icons as images instead of text, locking nicely to whole pixel values at any resolution. Compare the zoomed-in icon font version on the left with the crisp SVG version on the right.
Why SVG?
Icon font rendering issues
Icon fonts have always been a hack. We originally used a custom font with our icons as unicode symbols. This allowed us to include our icon font in our CSS bundle. Simply adding a class to any element would make our icons appear. We could then change the size and color on the fly using only CSS.
Unfortunately, even though these icons were vector shapes, they’d often render poorly on 1x displays. In Webkit-based browsers, you’d get blurry icons depending on the browser’s window width. Since our icons were delivered as text, sub-pixel rendering meant to improve text legibility actually made our icons look much worse.
Page rendering improvements
Since our SVG is injected directly into the markup (more on why we used this approach in a bit), we no longer see a flash of unstyled content as the icon font is downloaded, cached, and rendered.

Accessibility
As laid out in Death to Icon Fonts, some users override GitHub’s fonts. For dyslexics, certain typefaces can be more readable. To those changing their fonts, our font-based icons were rendered as empty squares. This messed up GitHub’s page layouts and didn’t provide any meaning. SVGs will display regardless of font overrides. For screen readers, SVG provides us the ability to add pronouncable alt attributes, or leave them off entirely.
Properly sized glyphs
For each icon, we currently serve a single glyph at all sizes. Since the loading of our site is dependent on the download of our icon font, we were forced to limit the icon set to just the essential 16px shapes. This led to some concessions on the visuals of each symbol since we’d optimized for the 16px grid. When scaling our icons up in blankslates or marketing pages, we’re still showing the 16px version of the icon. With SVGs, we can easily fork the entire icon set and offer more appropriate glyphs at any size we specify. We could have done this with our icon fonts, but then our users would need to download twice as much data. Possibly more.
Ease of authoring
Building custom fonts is hard. A few web apps have popped up to solve this pain. Internally, we’d built our own. With SVG, adding a new icon could be as trivial as dragging another SVG file into a directory.
We can animate them
We’re not saying we should, but we could, though SVG animation does have some practical applications—preloader animations, for example.
How
Our Octicons appear nearly 2500 times throughout GitHub’s codebase. Prior to SVG, Octicons were included as simple spans <span class="octicon octicon-alert"></span>. To switch to SVG, we first added a Rails helper for injecting SVG paths directly into to our markup. Relying on the helper allowed us to test various methods of delivering SVG to our staff before enabling it for the public. Should a better alternative to SVG come along, or if we need to revert back to icon fonts for any reason, we’d only have to change the output of the helper.
Helper usage
Input
<%= octicon(:symbol => "plus") %>
Output
<svg aria-hidden="true" class="octicon octicon-plus" width="12" height="16" role="img" version="1.1" viewBox="0 0 12 16">
<path d="M12 9H7v5H5V9H0V7h5V2h2v5h5v2z"></path>
</svg>Our approach
You can see we’ve landed on directly injecting the SVGs directly in our page markup. This allows us the flexibility to change the color of the icons with CSS using the fill: declaration on the fly.
Instead of an icon font, we now have a directory of SVG shapes whose paths are directly injected into the markup by our helper based on which symbol we choose. For example, if we want an alert icon, we call the helper <%= octicon(:symbol => "alert") %>. It looks for the icon of the same file name and injects the SVG.
We tried a number of approaches when adding SVG icons to our pages. Given the constraints of GitHub’s production environment, some were dead-ends.
- External .svg — We first attempted to serve a single external “svgstore”. We’d include individual sprites using the
<use>element. With our current cross-domain security policy and asset pipeline, we found it difficult to serve the SVG sprites externally. - SVG background images — This wouldn’t let us color our icons on the fly.
- SVGs linked via
<img>and thesrcattribute — This wouldn’t let us color our icons on the fly. - Embedding the entire “svgstore” in every view and using
<use>— It just didn’t feel quite right to embed every SVG shape we have on every single page throughout GitHub.com especially if a page didn’t include a single icon.
Performance
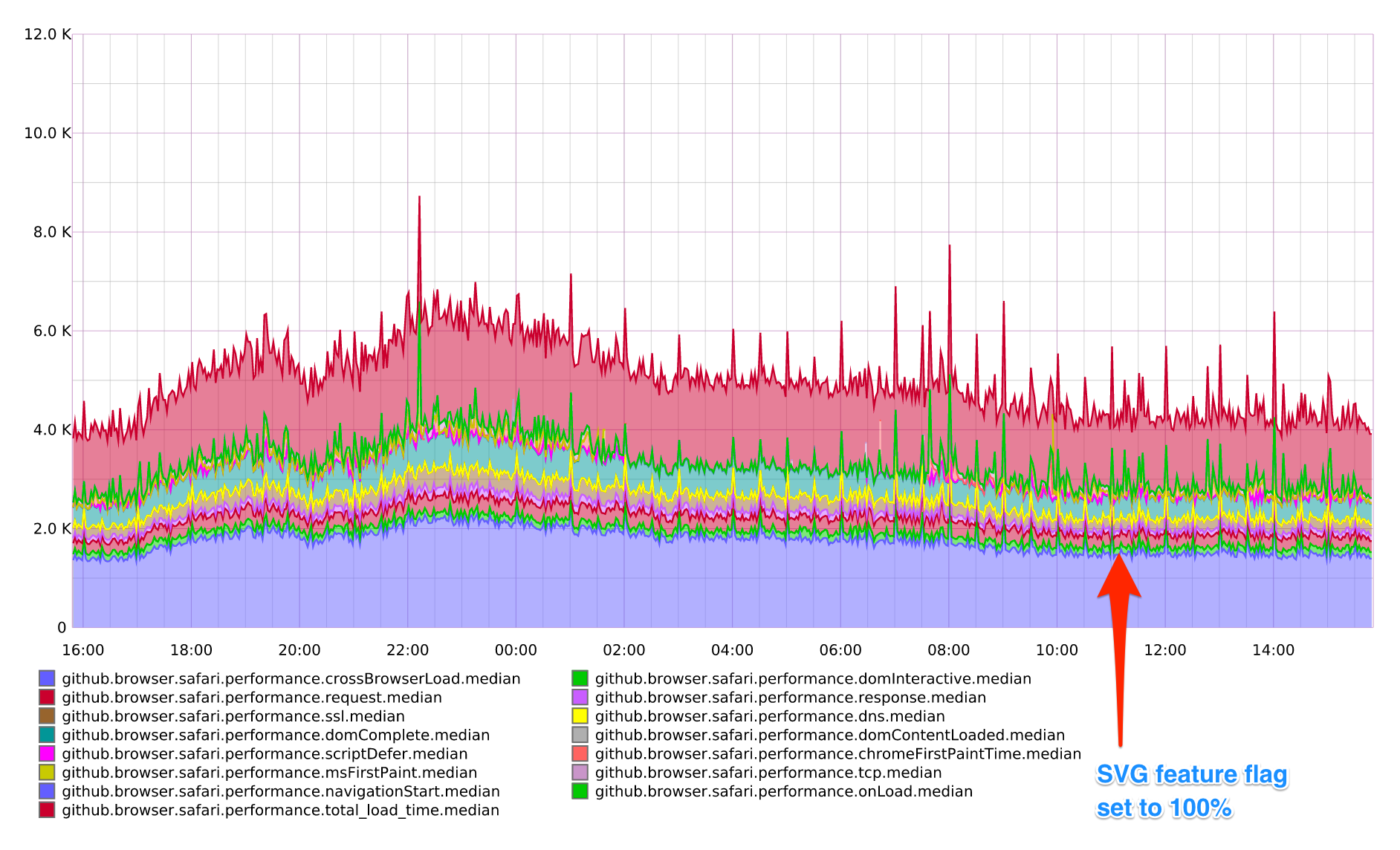
We’ve found there were no adverse effects on pageload or performance when switching to SVG. We’d hoped for a more dramatic drop in rendering times, but often performance has more to do with perception. Since SVG icons are being rendered like images in the page with defined widths and heights, the page doesn’t have nearly as much jank.
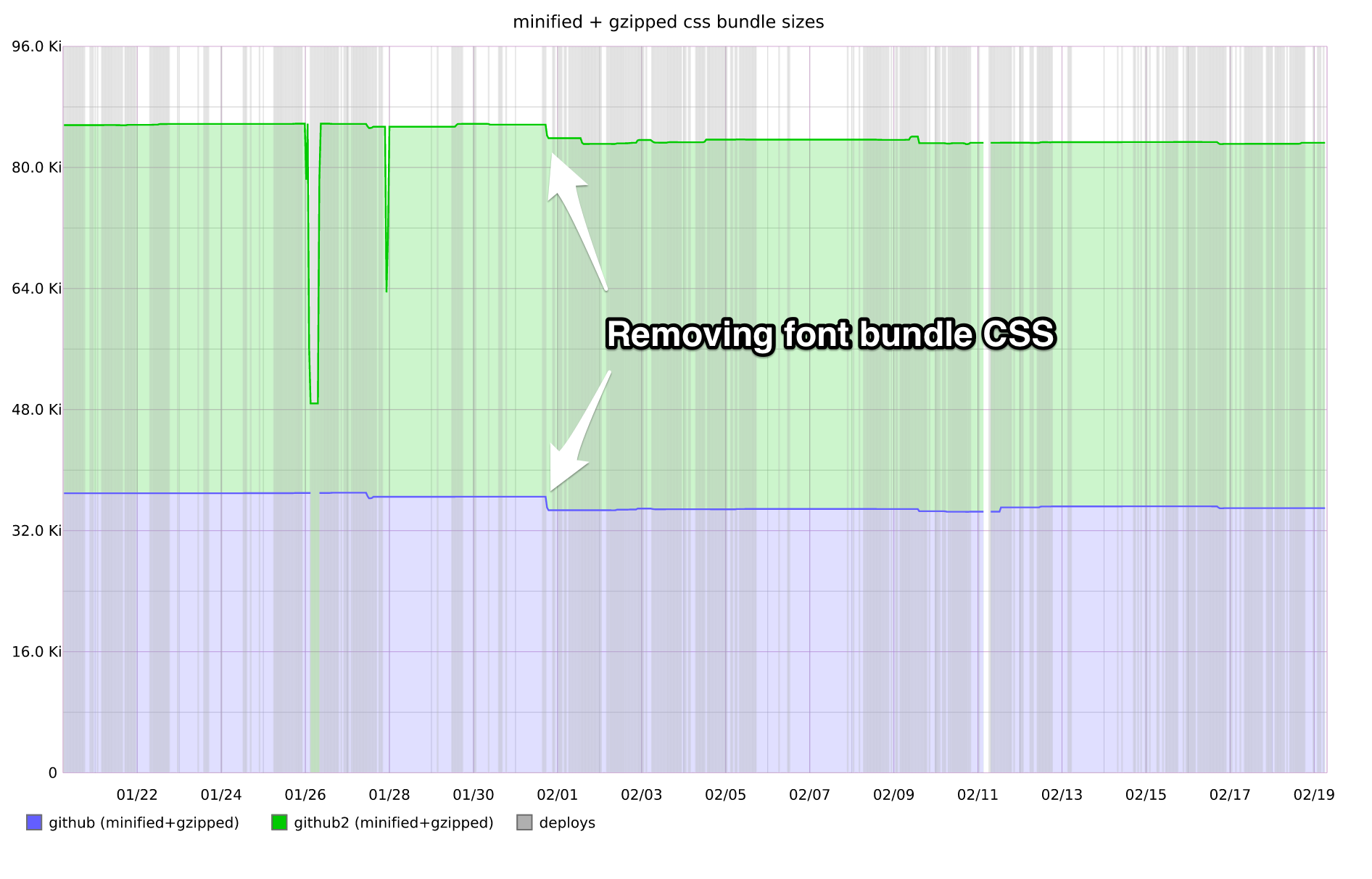
We were also able to kill a bit of bloat from our CSS bundles since we’re no longer serving the font CSS.
Drawbacks & Gotchas
- Firefox still has pixel-rounding errors in SVG, though the icon font had the same issue.
- You may have to wrap these SVGs with another div if you want to give them a background color.
- Since SVG is being delivered as an image, some CSS overrides might need to be considered. If you see anything weird in our layouts, let us know.
- Internet Explorer needs defined width and height attributes on the
svgelement in order for them to be sized correctly. - We were serving both SVG and our icon font during our transition. This would cause IE to crash while we were still applying font-family to each of the SVG icons. This was cleared up as soon as we transitioned fully to SVG.
TL;DR
By switching from icon fonts, we can serve our icons more easily, more quickly, and more accessibly. And they look better. Enjoy.

{kind=link}
{kind=link}