Eventually, any interesting software project will come to depend on another project, library, or framework. Git provides submodules to help with this. Submodules allow you to include or embed one or more repositories as a sub-folder inside another repository.
For many projects, submodules aren't the best answer (more on this below), and even at their best, working with submodules can be tricky, but let's start by looking at a straight-forward example.
Adding a Submodule
Let's say you're working on a project called Slingshot. You've got code for y-shaped stick and a rubber-band.

flickr photo shared by young@art under a Creative Commons ( BY ) license
At the same time, in another repository, you've got another project called Rock—it's just a generic rock library, but you think it'd be perfect for Slingshot.
You can add rock as a submodule of slingshot. In the slingshot repository:
git submodule add https://github.com/<user>/rock rock
At this point, you'll have a rock folder inside slingshot, but if you were to peek inside that folder, depending on your version of Git, you might see ... nothing.
Newer versions of Git will do this automatically, but older versions will require you to explicitly tell Git to download the contents of rock:
git submodule update --init --recursive
If everything looks good, you can commit this change and you'll have a rock folder in the slingshot repository with all the content from the rock repository.
On GitHub, the rock folder icon will have a little indicator showing that it is a submodule:
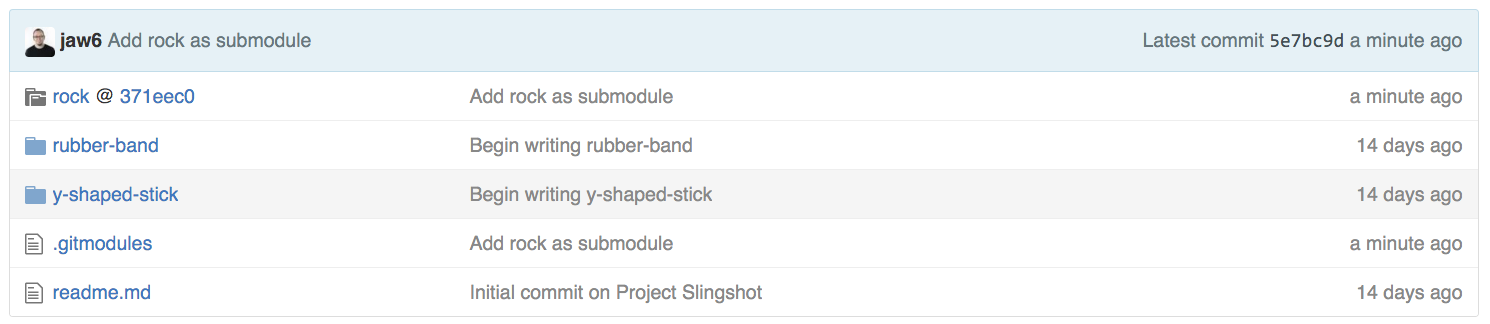
And clicking on the rock folder will take you over to the rock repository.
That's it! You've embedded the rock repository inside the slingshot repository. You can interact with all the content from rock as if it were a folder inside slingshot (because it is).
On the command-line, Git commands issued from slingshot (or any of the other folders, rubber-band and y-shaped-stick) will operate on the "parent repository", slingshot, but commands you issue from the rock folder will operate on just the rock repository:
cd ~/projects/slingshot
git log # log shows commits from Project Slingshot
cd ~/projects/slingshot/rubber-band
git log # still commits from Project Slingshot
cd ~/projects/slingshot/rock
git log # commits from Rock
Joining a project using submodules
Now, say you're a new collaborator joining Project Slingshot. You'd start by running git clone to download the contents of the slingshot repository. At this point, if you were to peek inside the rock folder, you'd see ... nothing.
Again, Git expects us to explicitly ask it to download the submodule's content. You can use git submodule update --init --recursive here as well, but if you're cloning slingshot for the first time, you can use a modified clone command to ensure you download everything, including any submodules:
git clone --recursive <project url>
Switching to submodules
It can be a little tricky to take an existing subfolder and turn it into an external dependency. Let's look at an example.
You're about to start a new project—a magic roll-back can–which also needs a rubber-band. Let's take the rubber-band you built for slingshot, split it out into a stand-alone repository, and then embed it into both projects via submodules.
You can take everything from the Project Slingshot's rubber-band folder and extract it into a new repository and even maintain the commit history.
Let's begin by extracting the contents of the rubber-band folder out of slingshot. You can use git filter-branch to do this, leaving you with just the commits related to rubber-band. The git filter-branch command will rewrite our repository's history, making it look as if the rubber-band folder had been it's own repository all along. For more information on git filter-branch, see this article.
The first step is to make a copy of slingshot to work on—the end-goal is for rubber-band to stand as its own repository, so leave slingshot as is. You can use cp with -r to recursively copy the entire slingshot folder to a new folder rubber-band.
cd ..
cp -r slingshot rubber-band
It looks like rubber-band is just another slingshot, but now, from the rubber-band repository, run git filter-branch:
cd rubber-band
pwd # (double check before proceeding!)
git filter-branch --subdirectory-filter rubber-band -- --all
At this point, you'll have a folder rubber-band, which is a repository that sort of resembles Project Slingshot, but it only has the files and commit history from the rubber-band folder.
Since you copied this from slingshot, the new repository will still have any remote tracking branches you setup when it was slingshot. You don't want to push rubber-band back onto slingshot. You want to push this to a new repository.
Create a new repository for rubber-band on GitHub, then update the remote for rubber-band. Assuming you were calling the remote origin, you could:
git remote set-url origin https://github.com/<user>/rubber-band
Then you can publish the new "generic rubber-band module" with git push.
Now that you've separated rubber-band into its own repository, you need to delete the old rubber-band folder from the slingshot repository:
git rm -r rubber-band
git commit -m "Remove rubber-band (preparing for submodule)"
Then update slingshot to use rubber-band as a submodule:
git submodule add https://github.com/<user>/rubber-band rubber-band
git commit -m "rubber-band submodule"
Like we saw before when we were adding rock, we now have a repository-in-a-repository. Three repositories, in fact: the "parent" repository slingshot, plus the two "sub" repositories, rock and rubber-band.
In addition, if we dive back into slingshot's history, we'll see the commits we originally made into rubber-band back when it was a folder—deleting the folder didn't erase any of the history. This can sometimes be a little confusing—since the rubber-band "child" repository has a copied-and-modified version of those old slingshot commits, it can sometimes feel like you're having déja vu.
Unfortunately, any collaborator who pulls slingshot at this point will have an empty rubber-band folder. You might want to remind your collaborators to run this command to ensure they have all the submodule's content:
git submodule update --init --recursive
You'll also want to add the rubber-band submodule to magic roll-back can. Luckily, all you need to do that is to follow the same procedure you used earlier when you added rock to slingshot, in "Adding a submodule."
cd ~/projects/roll-back-can
git submodule add https://github.com/<user>/rubber-band rubber-band
git commit -m "rubber-band submodule"
git submodule update --init --recursive
Advice on using submodules (or not)
- Before you add a repository as a submodule, first check to see if you have a better alternative available. Git submodules work well enough for simple cases, but these days there are often better tools available for managing dependencies than what Git submodules can offer. Modern languages like Go have friendly, Git-aware dependency management systems built-in from the start. Others, like Ruby's rubygems, Node.js' npm, or Cocoa's CocoaPods and Carthage, have been added by the programming community. Even front-end developers have tools like Bower to manage libraries and frameworks for client-side JavaScript and CSS.
- Remember that Git doesn't download submodule contents by default. If you're adding a submodule to an existing project, make sure anyone that works on the project knows they need to run commands like
git submodule update and git clone --recursive to ensure they get everything—this includes any automated deployment or testing service that might be involved in the project! We recommend you use something like our "Scripts to Rule Them All" to ensure that all collaborators and services have access to the same repository content everywhere.
- Submodules require you to carefully balance consistency and convenience. The setup used here strongly prefers consistency, at the cost of a little convenience. It's generally best to have a project's submodules locked to a specific SHA, so all collaborators receive the same content. But this setup also makes it difficult for developers in the "parent" repository to contribute changes back to the submodule repository.
- Remember that collaborators won't automatically see updates to submodules—if you update a submodule, you may need to remind your colleagues to run
git submodule update or they will likely see odd behavior.
- Managing dynamic, rapidly evolving or heavily co-dependent repositories with submodules can quickly become frustrating. This post was focused on simple, relatively static parent-child repository relationships. A future follow-up post will detail some strategies to help manage more complex submodule workflows.
Further reading