Posters featuring some extraordinary Octocat moments are now available in 8.5"x11", 18"x24", and 24"x36" sizes*. Check them out in the GitHub Shop

*Frames not included
Posters featuring some extraordinary Octocat moments are now available in 8.5"x11", 18"x24", and 24"x36" sizes*. Check them out in the GitHub Shop
*Frames not included
If you have source code in Subversion, Mercurial, Team Foundation Server, or another Git repository, you can now quickly and easily move that code to GitHub with the GitHub Importer. It will move your code and then notify you (via email or in your browser) when your newly populated GitHub repository is ready for action.
Access the GitHub Importer directly from https://import.github.com, or use the import feature to migrate your code when you create a new repository on GitHub.com. Your repository will join over 400,000 that have used this feature to move to GitHub!
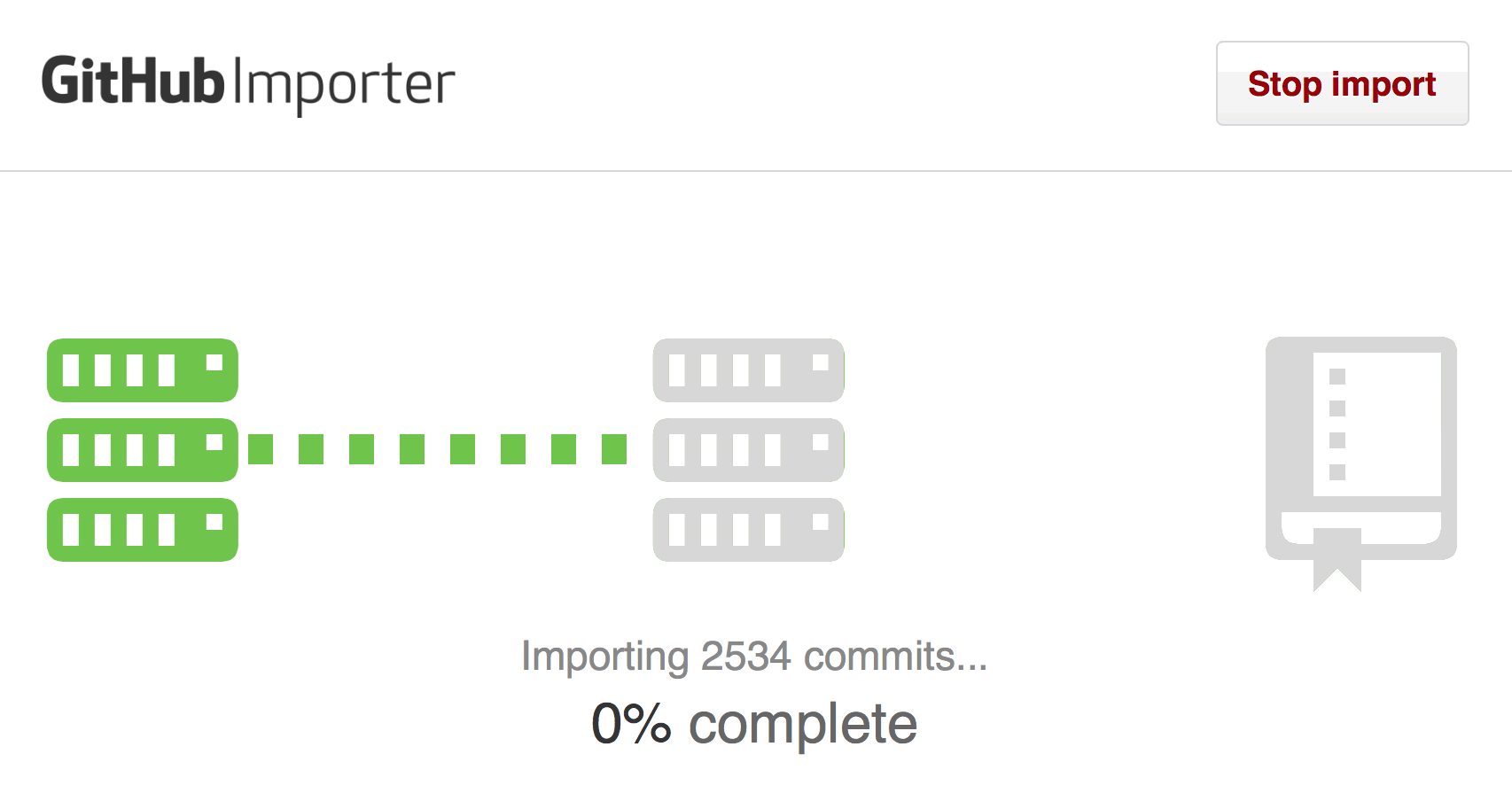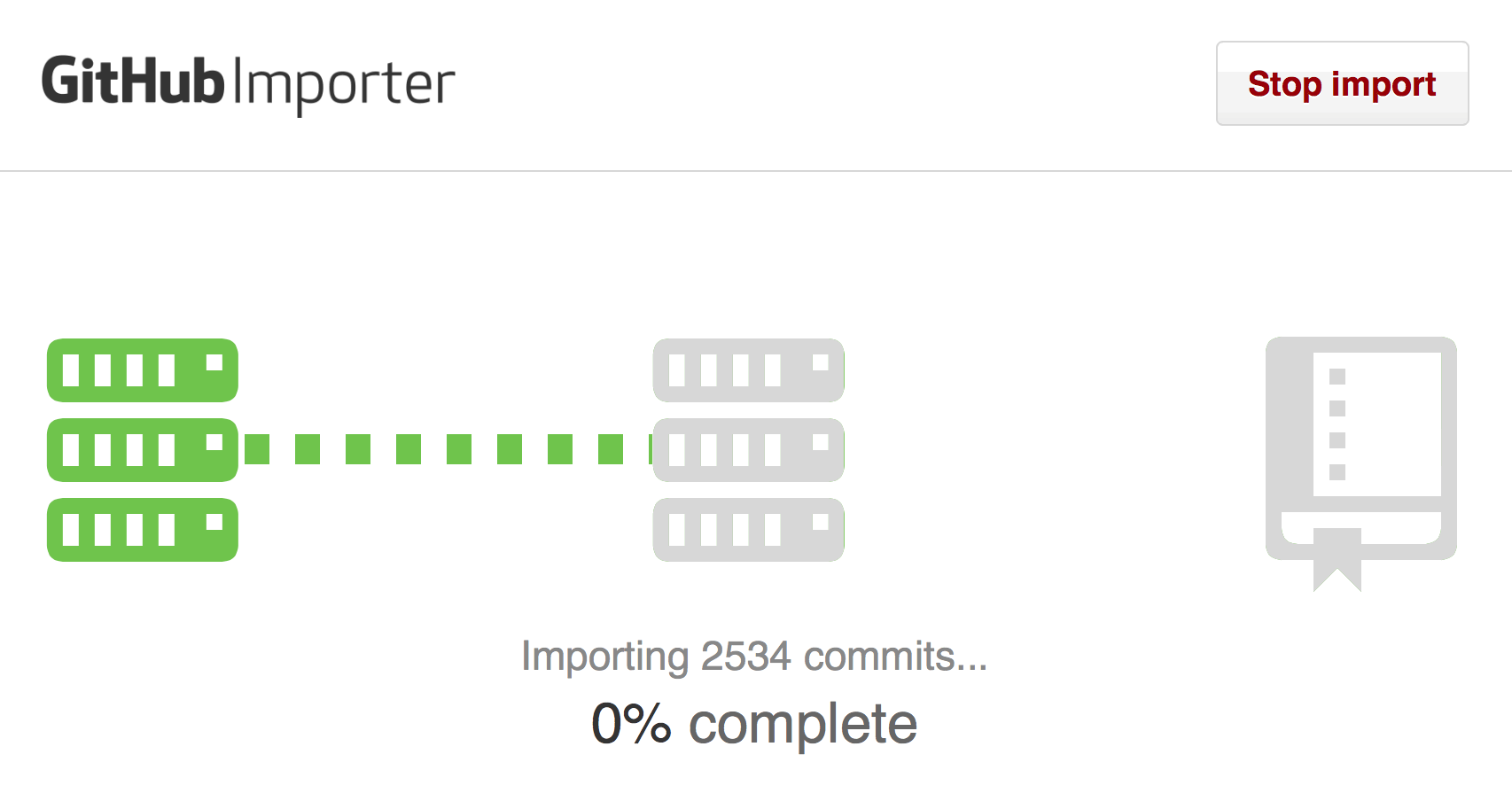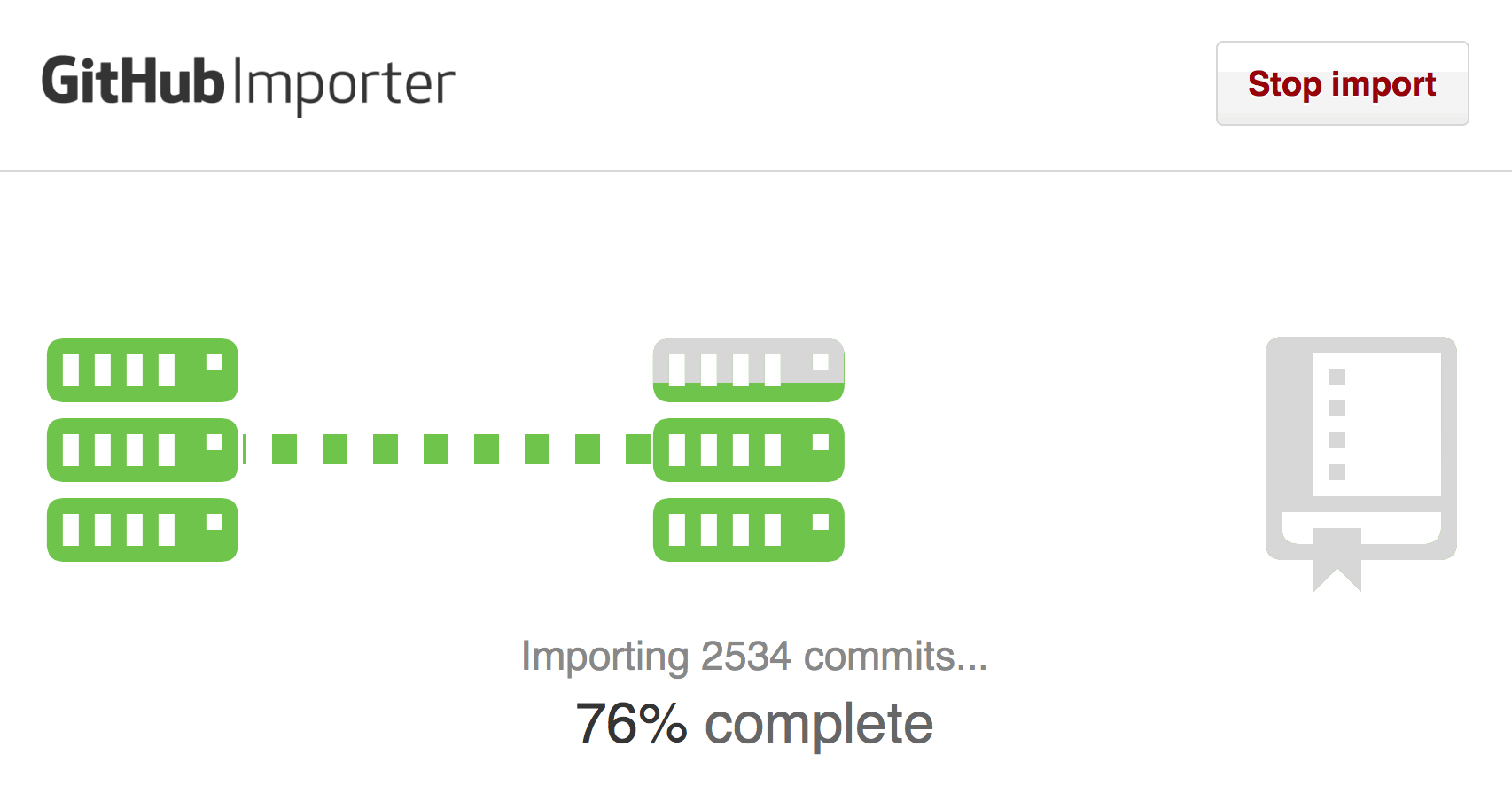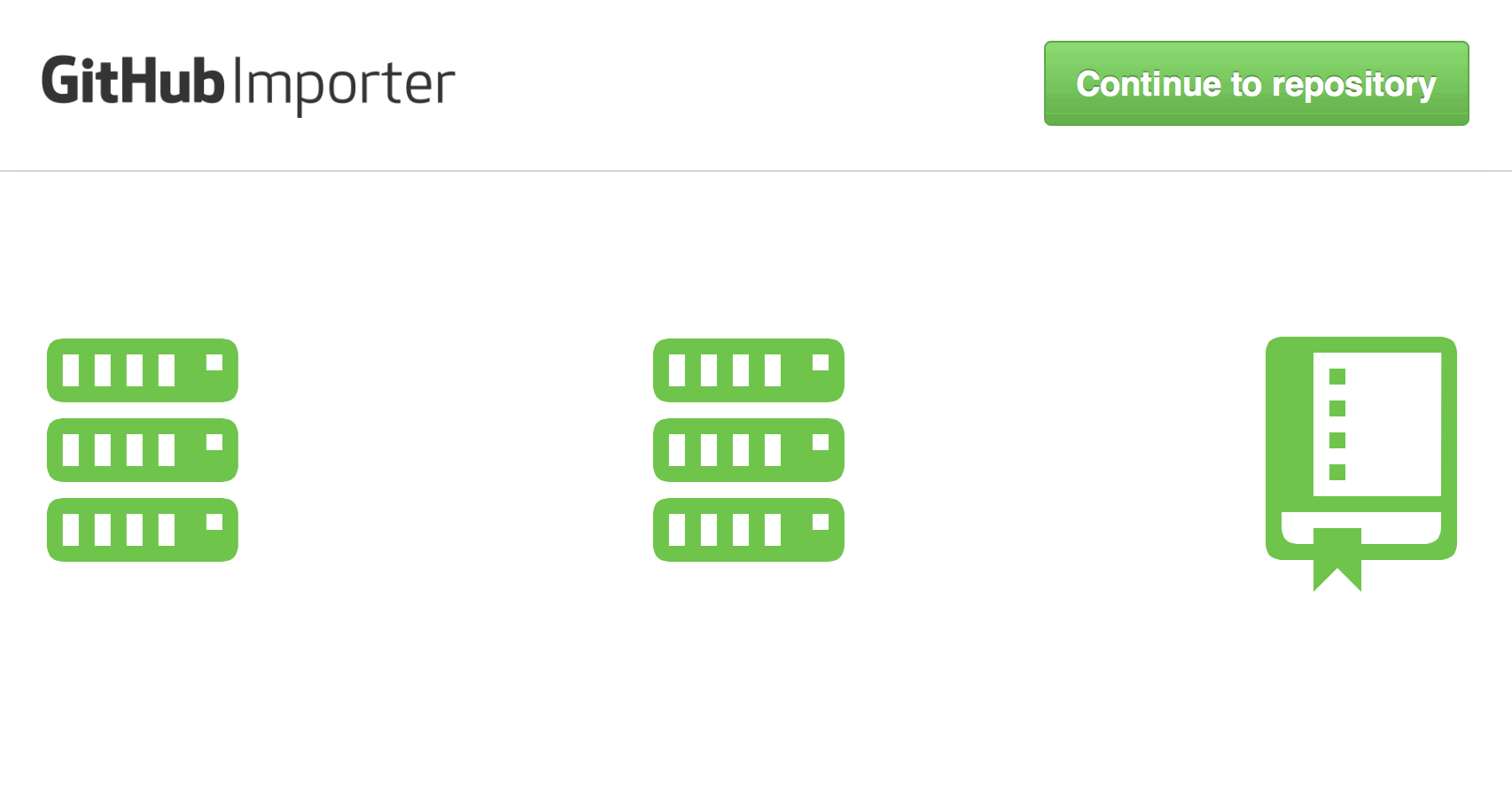
For more on migrating your source code, see "Importing your project to GitHub" in GitHub Help.
We are excited to announce the release of GitHub Enterprise 2.5. With this release, we’re introducing features and updates that will help development teams build software at scale with a focus on scalability, security, and management of GitHub Enterprise for development teams of any size.
It's important that your GitHub Enterprise instance can support the way you work without skipping a beat, even if your team is 10,000 strong and growing exponentially. In this release, we're introducing a better way to add new users to large installations, more ways to collaborate safely, and other tools and updates that will help support your team as it gets bigger.
You'll also find a round of updates from a clean and simple design refresh to added support for Subversion, and more. Ready to upgrade? Download GitHub Enterprise 2.5.
As your team grows, so does your GitHub Enterprise installation. For our customers with teams of tens of thousands of developers, the 2.5 release introduces clustering—a framework that helps administrators add more users to large installations.
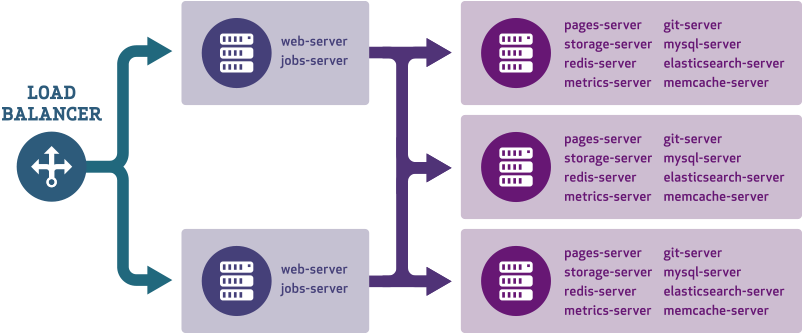
Clustering was specifically designed for very large installations but requires some additional administrative resources. Check out the documentation to see how it works or contact your GitHub account manager to discuss scaling options.
For teams working on bigger software projects, large CI farms or similar collections of clients that perfom git fetch for large amounts of data at almost the same time can cause a substantial CPU and RAM load on our fileservers. With GitHub Enterprise 2.5, we have improved our resilience to the degraded performance that can happen with "thundering herds."
GitHub Enterprise 2.4 included Protected Branches and Required Statuses to help teams collaborate safely: When you protect a branch, other developers can't delete or force-push to it. You can also specify status checks that collaborators need to pass before merging a pull request.
With GitHub Enterprise 2.5, we are kicking off a preview period for the Protected Branches API—allowing instance administrators to help maintain a project’s conventions at scale and make sure no one loses any work.
Protected branches and required status checks are configurable per repository. To start using the API, check out the documentation.
When you upgrade to GitHub Enterprise 2.5, parts of GitHub will look different. The repository and sign-in screens have updated designs that will make it easier to sign in and use GitHub from your browser.
The new repository design improves navigation, simplifies the page layout, and improves code performance under the hood. You can learn more about what's changed from our recent blog post on the new design. In the meantime, here’s a summary:
In addition to updating how repositories look, we have simplified the sign-in and authentication screens, so you can access your account more efficiently. The sign-up screen also includes a clearer sign-up link for new developers on your team who do not have a GitHub account, yet.
For teams who use SVN commands to interact with their repositories, the latest version of GitHub Enterprise extends support for Subversion to versions 1.8 and 1.9. You can now use newer Subversion clients with GitHub, including features from 1.8 and 1.9.
Check out the release notes to see what else is new or download GitHub Enterprise 2.5 now. You can also enable update checks to automatically update your instance whenever there is a new release.
To highlight the people behind projects we admire, we bring you the GitHub Developer Profile blog series.

Judy Gichoya is a medical doctor specializing in radiology, but she’s also an experienced programmer who is accelerating the growth of OpenMRS. With a mission to improve healthcare delivery in resource-constrained environments, OpenMRS is coordinating a global community to create a user-driven, open source medical record system platform that helps ease the work of health care providers. We asked Judy to share the story of how she became a developer, and what she’s learned from her work.
Erin: How long have you been developing software?
Judy: In 2001 I was enrolled at a local college in Nairobi to learn accounting when a family doctor noted that it would be more helpful for me to learn technology-related courses. I dropped off accounting and used the money that I had to enroll into IMIS, which taught technology and management concepts. I was required to work on a project in either Pascal or Visual Basic, and that's how I started programming. The challenge with being a student at this point was that we did not have enough teachers who understood programming, so most of the work that I did was self-taught by following tutorials on the Internet.
In 2003 I joined medical school and subsequently kept programming. I needed some money for school fees and joined a local company where in the evening after school I assembled their desktops. I assembled close to 10 computers every evening and hence got a good feel of the range of hardware available. I continued to learn more on programming, focusing on Java at that point. Around 2007 when I was doing my clinical rotations, the number of patients we treated with HIV-AIDS overwhelmed me, and I started wondering how the data for the care would be organized. A local nonprofit organization called AMPATH was starting to explore the use of OpenMRS, an open-source medical record system to help manage the patients and that’s how I got involved.
Erin: What programming languages do you use?
Judy: I started off using Java, but that can be a difficult language to learn in a developing country as it’s hard to find good teachers and mentors. I moved to using Python, Angular JS and various HTML5 technologies, and I wish I had made this move earlier. I am learning Node JS and tinkering with machine learning for some data analysis that I want to do in radiology.
Erin: Who did you look up to in your early days of software development?
Judy: A developer called Ben Wolfe, who was working on OpenMRS in the US, visited Kenya and provided local training to interested people. I found him very inspiring and knowledgeable. Doctors who write code have always surrounded me, and so it was a natural fit for me once I graduated as a medical doctor to continue writing code. I have interacted with many physicians who continue to do that both in the U.S. and worldwide. We all know diversity issues are a big problem, and I cannot say that I had any woman to look up to or work with when I started out.
Erin: Tell us about your journey into the world of software development
Judy: The very first time I saw a computer was in high school. We received a donation of 10 computers running Windows 3.1 for a computer lab that was used by more than 300 students. The school was looking for some volunteers to learn computers, and I jumped on the opportunity. This provided for guaranteed time using the computers, but my Agriculture teacher was very disappointed and thought it was a big mistake. We shared one teacher across the whole province, which meant several schools relied on him to teach a few days every month.
We were falling behind, so I started to study ahead of everyone else to help the 10 students who were going to seat a final examination in computers in order to graduate from high school. This experience sufficiently enabled me to be self driven in personalized learning, and taught me how to maximize use of available resources.
I had close to US$200 saved after graduation (actually from selling chicken). I bought a second-hand computer and took it home. We did not have electricity in my village home and I had to hide it from my dad who would not approve. I set up my computer in my uncle's house would go there and use it and then go back home.
When it finally came time to do programming, I modified a ‘hello world’ application to be ‘hello Judy’.
Erin: What resources did you have available when you first got into software development?
Judy: In 2002 while pursuing IMIS certification, Strathmore University had several computer labs that I could use, furnished with Internet. I made friends along the way who were interested in programming and so we had a good support group that could help each other.
When I started working at OpenMRS, their community was the biggest resource for helping me get started with Java programming. They were available on IRC and Google groups and once I learned how to use the Wiki to search previously-asked questions and ‘how to’ pages, things got a little better. Despite the experience that most open-source products are poorly documented, the large and vibrant OpenMRS community contributed a lot to my learning.
Erin: What have you learned as a developer?
Most of my work has been around medical record systems, and I can say that good computing saves lives. What has happened over the last few years is how remarkably easy it's become to develop software. And therefore the developer needs to be integrated within an ecosystem that's trying to tackle a problem whether it's business or for impact, and this is the only way I think to be relevant.
There have been lots of changes of perception about developers. Initially there was a myth that developers were weirdos, but now you know developers have become celebrities. Moreover there is lots of hype for looking for the next Google or the next Facebook and I think it's easy for other people to get caught up in the circus.
Erin: Is there any advice you’d give someone just getting into software development or open source?
Judy: Looking back on my experience, I would say stay passionate about what you care about and be persistent. Open source is not easy as you know, your questions can get answered two weeks later, or sometimes never answered, and so persistence is key. For those who are worried about income or business, there is a lot of opportunity in open source.
If you were starting out specifically in a limited resource setting, I would encourage you to learn languages that take a shorter time to become proficient in, and where you have available resources to make you successful.
Erin: Can you share some background on OpenMRS and how it’s changing global healthcare?
Judy: Around 2007, a group of 4 physicians working in global health in Kenya and Rwanda came together at the Medinfo San Francisco conference during break in a café to figure out a solution to scale up providing care in their countries. On napkins, they brainstormed the first data model that would lead to OpenMRS. Three developers initially worked on the project, but since day one, there was a strong desire to open source the project that led to a community of friends growing around OpenMRS.
Our experience is that people wanted tools to use that were local to their problems, and OpenMRS provided a starting point for them to tackle their specific problems. We had some academicians who had grants that were looking at health technology adoption and assessment in various countries. They never recommended OpenMRS, but the local initiatives picked up OpenMRS as the tool to use to get started. This led to several national implementations of OpenMRS including Rwanda, Kenya, Vietnam, Uganda, and Mozambique with more countries increasingly adopting OpenMRS to provide health care.
Erin: Tell us a bit about the community that is contributing to OpenMRS. How has it changed over the years? What are some urgent needs you have?
Judy: What started off as three developers working on OpenMRS full-time has resulted into this large community. Our community is organized around implementers, people who do not necessarily have development expertise but use our software, and developers who actively write code for OpenMRS. We have developers from all over the world as we are in use in over 42 countries (https://atlas.openmrs.org/).
One thing we have not been able to do well has been to track forked off code contributions. Every month we have a surprise article or new development /use case of OpenMRS that we were not aware of. I guess this can be considered a success in the open source community. But it would be good to convince people who have forked code to contribute back to the community.
Running our diversity statistics was rather embarrassing since this is an area we lag behind in. We have organized developer levels that people can work towards and we had no /dev/5 developers who were female. We need more people working on OpenMRS, and are working towards a certification program powered by open source learning. We still are looking for funding to support our MOOC launch. Most importantly, our mission is that information is care. Most of the areas where we work have very limited resources, and we only tackle one end of the big global health problem by providing software. We need resources and partners to help us accelerate tackling the health problem in limited resource settings.
Erin: Where do you see the future headed for open source software in healthcare?
Judy: As we grow older and people live longer, caring for patients is increasingly more complex. In developing countries, open source technologies support leapfrogging through the health divide to take care of the high burden of communicable and noncommunicable diseases. For developed countries, the health care data is locked into vendor systems and doctors cannot get evidence by quickly searching the data. For example, I am using OpenMRS to run a disease registry to track outcomes of patients that receive treatment with Yttirum 90 for advanced liver cancer in the US. Before introducing this project, a solution had been sought for years and required a huge capital cost. I see open source playing a big role in these fields to provide such flexibility
Learn more about Judy and her work on her website, or get in touch on Twitter.
Despite the best efforts of its writers, software has vulnerabilities, and GitHub is no exception. Finding, fixing, and learning from past bugs is a critical part of keeping our users and their data safe on the Internet. Two years ago, we launched the GitHub Security Bug Bounty and it's been an incredible success. By rewarding the talented and dedicated researchers in the security industry, we discover and fix security vulnerabilities before they can be exploited.
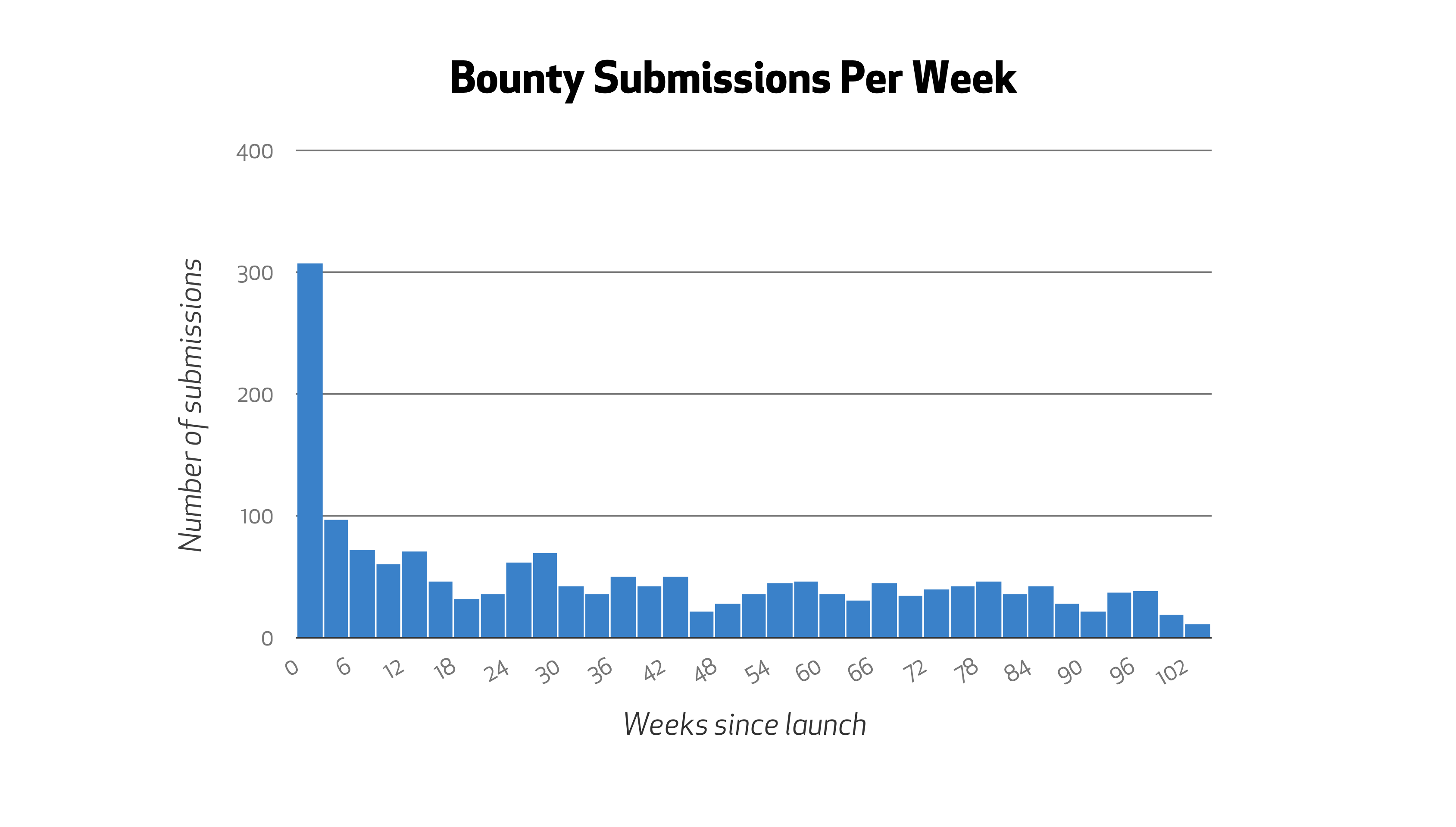
Of 7,050 submissions in the past two years, 1,772 warranted further review, helping us to identify and fix vulnerabilities spanning all of the OWASP top 10 vulnerability classifications. 58 unique researchers earned a cumulative $95,300 for the 102 medium to high risk vulnerabilities they reported. This chart shows the breakdown of payouts by severity and OWASP classification:
| A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A0 | Sum | |
| Low | 4 | 5 | 11.5 | 1 | 8 | 11 | 5 | 7 | 3 | 3.5 | 1 | 60 |
| Medium | 2 | 1 | 12 | 0 | 1 | 1 | 5 | 1 | 0 | 3 | 0 | 26 |
| High | 2 | 2 | 3.5 | 0 | 2 | 1 | 0 | 0.5 | 0 | 0 | 2 | 13 |
| Critical | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 |
| Sum | 11 | 8 | 27 | 1 | 11 | 13 | 10 | 8.5 | 4 | 6.5 | 3 | 102 |
We love it when a reported vulnerability ends up not being our fault. @kelunik and @bwoebi reported a browser vulnerability, causing GitHub's cookies to be sent to other domains. @ealf reported a browser bug, bypassing our JavaScript same-origin policy checks. We were able to protect our users from these vulnerabilities months before the browser vendors released patches.
Another surprising bug was reported by @cryptosense, who found that some RSA key generators were creating SSH keys that were trivially factorable. We ended up finding and revoking 309 weak RSA keys and now have validations checking if keys are factorable by the first 10,000 primes.
In the first year of the bounty program, we saw reports mostly about our web services. In 2015, we received a number of reports for vulnerabilities in our desktop apps. @tunz reported a clever exploit against GitHub for Mac, allowing remote code execution. Shortly thereafter, @joernchen reported a similar bug in GitHub for Windows, following up a few months later with a separate client-side remote code execution vulnerability in Git Large File Storage (LFS).
In 2015 we saw an amazing increase in the number of bounties donated to a good cause. GitHub matches bounties donated to 501(c)(3) organizations, and with the help of our researchers we contributed to the EFF, Médecins Sans Frontières, the Ada Initiative, the Washington State Burn Foundation, and the Tor Project. A big thanks to @ealf, @LukasReschke, @arirubinstein, @cryptosense, @bureado, @vito, and @s-rah for their generosity.
In the first two years of the program, we paid researchers nearly $100,000. That's a great start, but we hope to further increase participation in the program. So, fire up your favorite proxy and start poking at GitHub.com. When you find a vulnerability, report it and join the ranks of our leaderboard. Happy hacking!
Last week GitHub was unavailable for two hours and six minutes. We understand how much you rely on GitHub and consider the availability of our service one of the core features we offer. Over the last eight years we have made considerable progress towards ensuring that you can depend on GitHub to be there for you and for developers worldwide, but a week ago we failed to maintain the level of uptime you rightfully expect. We are deeply sorry for this, and would like to share with you the events that took place and the steps we’re taking to ensure you're able to access GitHub.
At 00:23am UTC on Thursday, January 28th, 2016 (4:23pm PST, Wednesday, January 27th) our primary data center experienced a brief disruption in the systems that supply power to our servers and equipment. Slightly over 25% of our servers and several network devices rebooted as a result. This left our infrastructure in a partially operational state and generated alerts to multiple on-call engineers. Our load balancing equipment and a large number of our frontend applications servers were unaffected, but the systems they depend on to service your requests were unavailable. In response, our application began to deliver HTTP 503 response codes, which carry the unicorn image you see on our error page.
Our early response to the event was complicated by the fact that many of our ChatOps systems were on servers that had rebooted. We do have redundancy built into our ChatOps systems, but this failure still caused some amount of confusion and delay at the very beginning of our response. One of the biggest customer-facing effects of this delay was that status.github.com wasn't set to status red until 00:32am UTC, eight minutes after the site became inaccessible. We consider this to be an unacceptably long delay, and will ensure faster communication to our users in the future.
Initial notifications for unreachable servers and a spike in exceptions related to Redis connectivity directed our team to investigate a possible outage in our internal network. We also saw an increase in connection attempts that pointed to network problems. While later investigation revealed that a DDoS attack was not the underlying problem, we spent time early on bringing up DDoS defenses and investigating network health. Because we have experience mitigating DDoS attacks, our response procedure is now habit and we are pleased we could act quickly and confidently without distracting other efforts to resolve the incident.
With our DDoS shields up, the response team began to methodically inspect our infrastructure and correlate these findings back to the initial outage alerts. The inability to reach all members of several Redis clusters led us to investigate uptime for devices across the facility. We discovered that some servers were reporting uptime of several minutes, but our network equipment was reporting uptimes that revealed they had not rebooted. Using this, we determined that all of the offline servers shared the same hardware class, and the ones that rebooted without issue were a different hardware class. The affected servers spanned many racks and rows in our data center, which resulted in several clusters experiencing reboots of all of their member servers, despite the clusters' members being distributed across different racks.
As the minutes ticked by, we noticed that our application processes were not starting up as expected. Engineers began taking a look at the process table and logs on our application servers. These explained that the lack of backend capacity was a result of processes failing to start due to our Redis clusters being offline. We had inadvertently added a hard dependency on our Redis cluster being available within the boot path of our application code.
By this point, we had a fairly clear picture of what was required to restore service and began working towards that end. We needed to repair our servers that were not booting, and we needed to get our Redis clusters back up to allow our application processes to restart. Remote access console screenshots from the failed hardware showed boot failures because the physical drives were no longer recognized. One group of engineers split off to work with the on-site facilities technicians to bring these servers back online by draining the flea power to bring them up from a cold state so the disks would be visible. Another group began rebuilding the affected Redis clusters on alternate hardware. These efforts were complicated by a number of crucial internal systems residing on the offline hardware. This made provisioning new servers more difficult.
Once the Redis cluster data was restored onto standby equipment, we were able to bring the Redis-server processes back online. Internal checks showed application processes recovering, and a healthy response from the application servers allowed our HAProxy load balancers to return these servers to the backend server pool. After verifying site operation, the maintenance page was removed and we moved to status yellow. This occurred two hours and six minutes after the initial outage.
The following hours were spent confirming that all systems were performing normally, and verifying there was no data loss from this incident. We are grateful that much of the disaster mitigation work put in place by our engineers was successful in guaranteeing that all of your code, issues, pull requests, and other critical data remained safe and secure.
Complex systems are defined by the interaction of many discrete components working together to achieve an end result. Understanding the dependencies for each component in a complex system is important, but unless these dependencies are rigorously tested it is possible for systems to fail in unique and novel ways. Over the past week, we have devoted significant time and effort towards understanding the nature of the cascading failure which led to GitHub being unavailable for over two hours. We don’t believe it is possible to fully prevent the events that resulted in a large part of our infrastructure losing power, but we can take steps to ensure recovery occurs in a fast and reliable manner. We can also take steps to mitigate the negative impact of these events on our users.
We identified the hardware issue resulting in servers being unable to view their own drives after power-cycling as a known firmware issue that we are updating across our fleet. Updating our tooling to automatically open issues for the team when new firmware updates are available will force us to review the changelogs against our environment.
We will be updating our application’s test suite to explicitly ensure that our application processes start even when certain external systems are unavailable and we are improving our circuit breakers so we can gracefully degrade functionality when these backend services are down. Obviously there are limits to this approach and there exists a minimum set of requirements needed to serve requests, but we can be more aggressive in paring down the list of these dependencies.
We are reviewing the availability requirements of our internal systems that are responsible for crucial operations tasks such as provisioning new servers so that they are on-par with our user facing systems. Ultimately, if these systems are required to recover from an unexpected outage situation, they must be as reliable as the system being recovered.
A number of less technical improvements are also being implemented. Strengthening our cross-team communications would have shaved minutes off the recovery time. Predefining escalation strategies during situations that require all hands on deck would have enabled our incident coordinators to spend more time managing recovery efforts and less time navigating documentation. Improving our messaging to you during this event would have helped you better understand what was happening and set expectations about when you could expect future updates.
We realize how important GitHub is to the workflows that enable your projects and businesses to succeed. All of us at GitHub would like to apologize for the impact of this outage. We will continue to analyze the events leading up to this incident and the steps we took to restore service. This work will guide us as we improve the systems and processes that power GitHub.
GitHub Pages is now running the latest major version of Jekyll, Jekyll 3.0, and with it, many of the complexities associated with publishing have been further simplified, meaning it's now easier and faster to publish beautiful sites for you and your projects.
If you're familiar with using Markdown to author issues, pull requests, or comments on GitHub.com, writing Markdown for GitHub Pages sites will now be equally as intuitive. Markdown may be the lingua franca of the open source community, but that doesn't mean that certain regional dialects haven't emerged over the years. Traditionally, authors have had to choose between several different Markdown engines, each with their own interpretations of how Markdown should work.
Starting May 1st, 2016, GitHub Pages will only support kramdown, Jekyll's default Markdown engine. If you are currently using Rdiscount or Redcarpet we've enabled kramdown's GitHub-flavored Markdown support by default, meaning kramdown should have all the features of the two deprecated Markdown engines, so the transition should be as simple as updating the Markdown setting to kramdown in your site's configuration (or removing it entirely) over the course of the next three months.
GitHub Pages now only supports Rouge, a pure-Ruby syntax highlighter, meaning you no longer need to install Python and Pygments to preview your site locally. If you were previously using Pygments for highlighting, the two libraries are feature compatible, so we'll swap Rouge in for Pygments when we build your site, to ensure a seamless transition.
Traditionally, highlighting in Jekyll has been implemented via the {% highlight %} Liquid tag, forcing you to leave a pure-Markdown experience. With kramdown and Rouge as the new defaults, syntax highlighting on GitHub Pages should work like you'd expect it to work anywhere else on GitHub, with native support for backtick-style fenced code blocks right within the Markdown.
Jekyll 3.0 offers several improvements for previewing and optimizing your site locally. For one, local builds are significantly faster, meaning you can preview your changes in near real time, and with incremental regeneration support (experimental), builds can be even faster still.
Jekyll 3.0 also introduces a liquid profiler. By adding --profile to the build or serve command, Jekyll will analyze your site's build time, so you can see exactly where things can be sped up, ensuring you spend more time authoring content, and less time waiting for your site to build.
The Jekyll 3.0 upgrade will introduce two additional changes that may affect a small subset of users:
Jekyll no longer supports relative permalinks. This has been the default since Jekyll 2.0, and is only an issue if you explicitly added relative_permalinks: true to your site's configuration. Going forward, regardless of your site's configuration, if you add the permalink directive to a page's YAML front matter, the path should be relative to the site's root directory, not the page's parent.
Starting May 1st, 2016, GitHub Pages will no longer support Textile. If you are currently using Textile (Redcloth) to author your Jekyll site, you'll need to convert your site to use Markdown instead.
The changes introduced today promise to make GitHub Pages a faster, more intuitive experience for new and power users alike. For more information on upgrading, see Jekyll's 3.0 upgrade guide, and if you have any questions about Jekyll 3.0, the upgrade process, or just GitHub Pages in general, please get in touch with us.
Happy (simplified) publishing!
Eventually, any interesting software project will come to depend on another project, library, or framework. Git provides submodules to help with this. Submodules allow you to include or embed one or more repositories as a sub-folder inside another repository.
For many projects, submodules aren't the best answer (more on this below), and even at their best, working with submodules can be tricky, but let's start by looking at a straight-forward example.
Let's say you're working on a project called Slingshot. You've got code for y-shaped stick and a rubber-band.

flickr photo shared by young@art under a Creative Commons ( BY ) license
At the same time, in another repository, you've got another project called Rock—it's just a generic rock library, but you think it'd be perfect for Slingshot.
You can add rock as a submodule of slingshot. In the slingshot repository:
git submodule add https://github.com/<user>/rock rock
At this point, you'll have a rock folder inside slingshot, but if you were to peek inside that folder, depending on your version of Git, you might see ... nothing.
Newer versions of Git will do this automatically, but older versions will require you to explicitly tell Git to download the contents of rock:
git submodule update --init --recursive
If everything looks good, you can commit this change and you'll have a rock folder in the slingshot repository with all the content from the rock repository.
On GitHub, the rock folder icon will have a little indicator showing that it is a submodule:
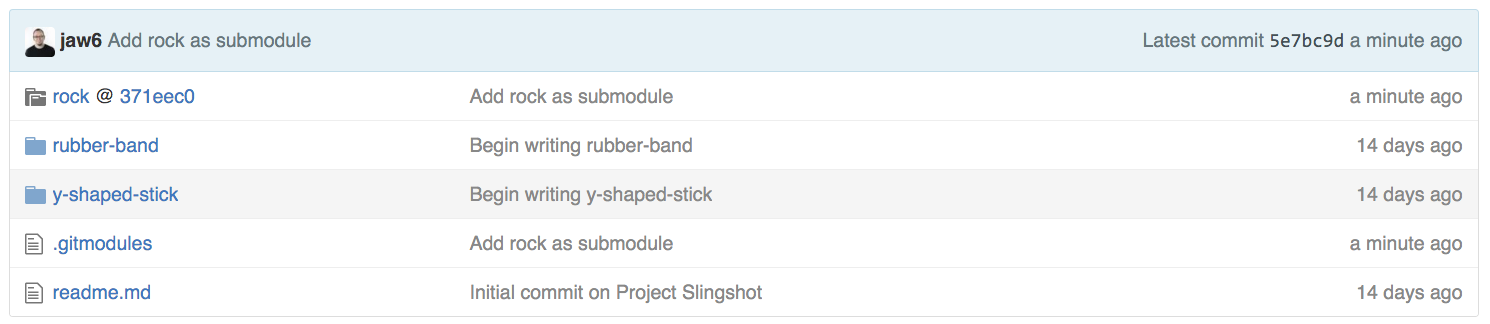
And clicking on the rock folder will take you over to the rock repository.
That's it! You've embedded the rock repository inside the slingshot repository. You can interact with all the content from rock as if it were a folder inside slingshot (because it is).
On the command-line, Git commands issued from slingshot (or any of the other folders, rubber-band and y-shaped-stick) will operate on the "parent repository", slingshot, but commands you issue from the rock folder will operate on just the rock repository:
cd ~/projects/slingshot
git log # log shows commits from Project Slingshot
cd ~/projects/slingshot/rubber-band
git log # still commits from Project Slingshot
cd ~/projects/slingshot/rock
git log # commits from Rock
Now, say you're a new collaborator joining Project Slingshot. You'd start by running git clone to download the contents of the slingshot repository. At this point, if you were to peek inside the rock folder, you'd see ... nothing.
Again, Git expects us to explicitly ask it to download the submodule's content. You can use git submodule update --init --recursive here as well, but if you're cloning slingshot for the first time, you can use a modified clone command to ensure you download everything, including any submodules:
git clone --recursive <project url>
It can be a little tricky to take an existing subfolder and turn it into an external dependency. Let's look at an example.
You're about to start a new project—a magic roll-back can–which also needs a rubber-band. Let's take the rubber-band you built for slingshot, split it out into a stand-alone repository, and then embed it into both projects via submodules.
You can take everything from the Project Slingshot's rubber-band folder and extract it into a new repository and even maintain the commit history.
Let's begin by extracting the contents of the rubber-band folder out of slingshot. You can use git filter-branch to do this, leaving you with just the commits related to rubber-band. The git filter-branch command will rewrite our repository's history, making it look as if the rubber-band folder had been it's own repository all along. For more information on git filter-branch, see this article.
The first step is to make a copy of slingshot to work on—the end-goal is for rubber-band to stand as its own repository, so leave slingshot as is. You can use cp with -r to recursively copy the entire slingshot folder to a new folder rubber-band.
cd ..
cp -r slingshot rubber-band
It looks like rubber-band is just another slingshot, but now, from the rubber-band repository, run git filter-branch:
cd rubber-band
pwd # (double check before proceeding!)
git filter-branch --subdirectory-filter rubber-band -- --all
At this point, you'll have a folder rubber-band, which is a repository that sort of resembles Project Slingshot, but it only has the files and commit history from the rubber-band folder.
Since you copied this from slingshot, the new repository will still have any remote tracking branches you setup when it was slingshot. You don't want to push rubber-band back onto slingshot. You want to push this to a new repository.
Create a new repository for rubber-band on GitHub, then update the remote for rubber-band. Assuming you were calling the remote origin, you could:
git remote set-url origin https://github.com/<user>/rubber-band
Then you can publish the new "generic rubber-band module" with git push.
Now that you've separated rubber-band into its own repository, you need to delete the old rubber-band folder from the slingshot repository:
git rm -r rubber-band
git commit -m "Remove rubber-band (preparing for submodule)"
Then update slingshot to use rubber-band as a submodule:
git submodule add https://github.com/<user>/rubber-band rubber-band
git commit -m "rubber-band submodule"
Like we saw before when we were adding rock, we now have a repository-in-a-repository. Three repositories, in fact: the "parent" repository slingshot, plus the two "sub" repositories, rock and rubber-band.
In addition, if we dive back into slingshot's history, we'll see the commits we originally made into rubber-band back when it was a folder—deleting the folder didn't erase any of the history. This can sometimes be a little confusing—since the rubber-band "child" repository has a copied-and-modified version of those old slingshot commits, it can sometimes feel like you're having déja vu.
Unfortunately, any collaborator who pulls slingshot at this point will have an empty rubber-band folder. You might want to remind your collaborators to run this command to ensure they have all the submodule's content:
git submodule update --init --recursive
You'll also want to add the rubber-band submodule to magic roll-back can. Luckily, all you need to do that is to follow the same procedure you used earlier when you added rock to slingshot, in "Adding a submodule."
cd ~/projects/roll-back-can
git submodule add https://github.com/<user>/rubber-band rubber-band
git commit -m "rubber-band submodule"
git submodule update --init --recursive
git submodule update and git clone --recursive to ensure they get everything—this includes any automated deployment or testing service that might be involved in the project! We recommend you use something like our "Scripts to Rule Them All" to ensure that all collaborators and services have access to the same repository content everywhere.git submodule update or they will likely see odd behavior.git filter-branch
Mark your calendars. GitHub has a fresh lineup of events for 2016 – including two new European conferences, GitHub Satellite and CodeConf Copenhagen.

Git Merge is the pre-eminent Git conference: a full-day event featuring technical content and training workshops for Git users of all levels. Git Merge is dedicated to amplifying new voices from the Git community and to showcasing the most thought-provoking projects from contributors, maintainers, and community managers around the world. Tickets are now on sale. Interested in speaking at Git Merge? Send us an overview of your talk by February 5th. We’d love to hear from you.
The first ever European conference in the GitHub Universe event series, GitHub Satellite is a celebration of the latest and greatest in software. Join us to learn how developers, founders, and activists work to create impactful technologies. Great software is about more than code; at Satellite, we'll showcase how the community is tackling the newest and most difficult challenges posed by the modern development workflow.
This year CodeConf, a two-day conference for the open souce community, moves to the West Coast. At CodeConf we will get together to discuss best practices in open source, documentation, community-building, and innovative technical hacks. Check out the lineup from last year's event in Nashville to get a taste of what you can expect.
GitHub Universe is returning to Pier 70 for a two-day conference celebrating technologists and developers from across the GitHub community. Last year, we heard from people who are improving people's lives using technology and redefining how software is built. This year, you can look forward to an even better Universe.
CodeConf comes to Copenhagen for a conversation with the European open source community. Thought-provoking sessions and networking opportunities are just a few of the reasons we hope you’ll join us.
For updates on all of these events as they emerge, keep your eye on https://twitter.com/github.
On Thursday, January 28, 2016 at 00:23am UTC, we experienced a severe service outage that impacted GitHub.com. We know that any disruption in our service can impact your development workflow, and are truly sorry for the outage. While our engineers are investigating the full scope of the incident, I wanted to quickly share an update on the situation with you.
A brief power disruption at our primary data center caused a cascading failure that impacted several services critical to GitHub.com's operation. While we worked to recover service, GitHub.com was unavailable for two hours and six minutes. Service was fully restored at 02:29am UTC. Last night we completed the final procedure to fully restore our power infrastructure.
Millions of people and businesses depend on GitHub. We know that our community feels the effects of our site going down deeply. We’re actively taking measures to improve our resilience and response time, and will share details from these investigations.

You’ll notice there’s a new Markdown text-formatting toolbar on all the comment fields throughout GitHub. While you've always been able to use Markdown to format your text with links, headers, italics, and lists, the new toolbar allows you to do so without learning Markdown syntax.
The toolbar includes a limited set of tools that gets out of the way of experts, but helps those new to GitHub to write just as clearly, and expressively as anyone else. Neat.
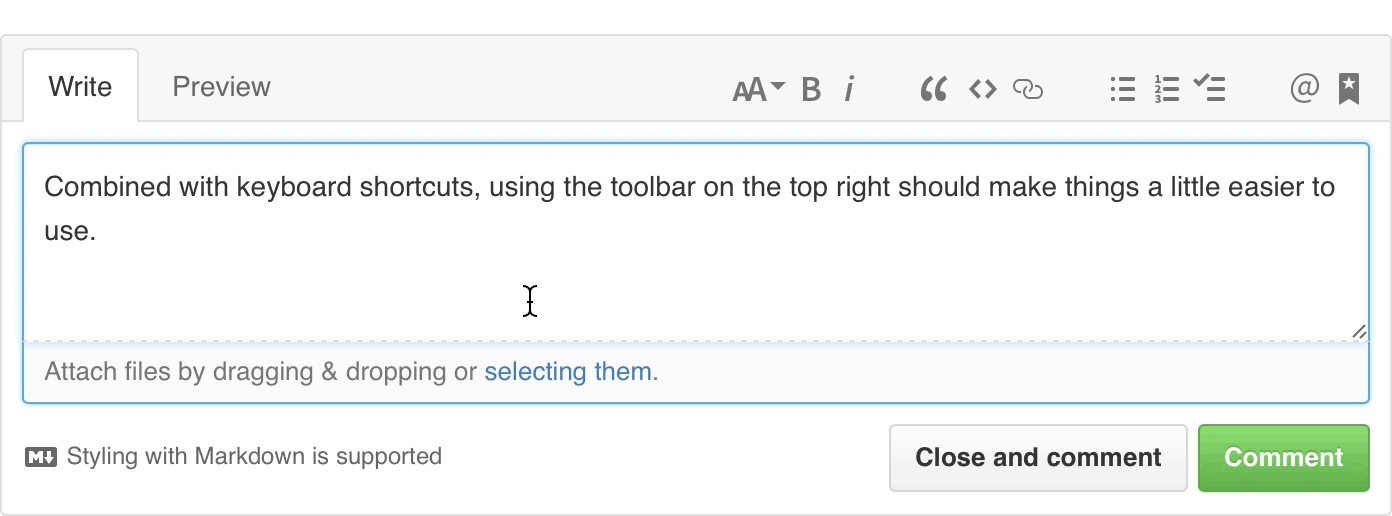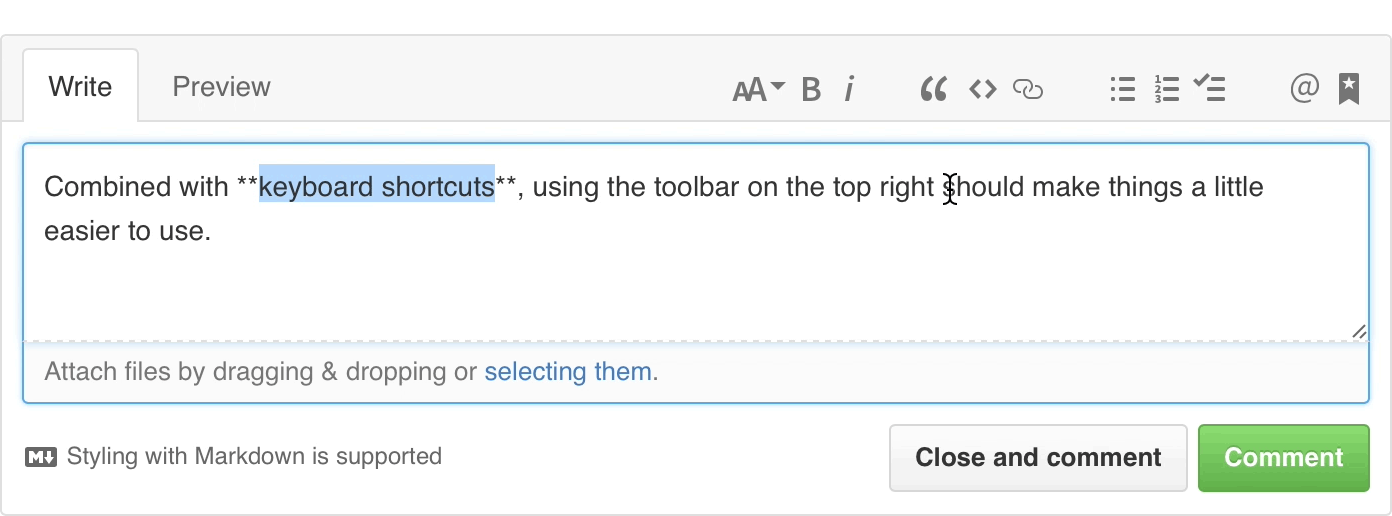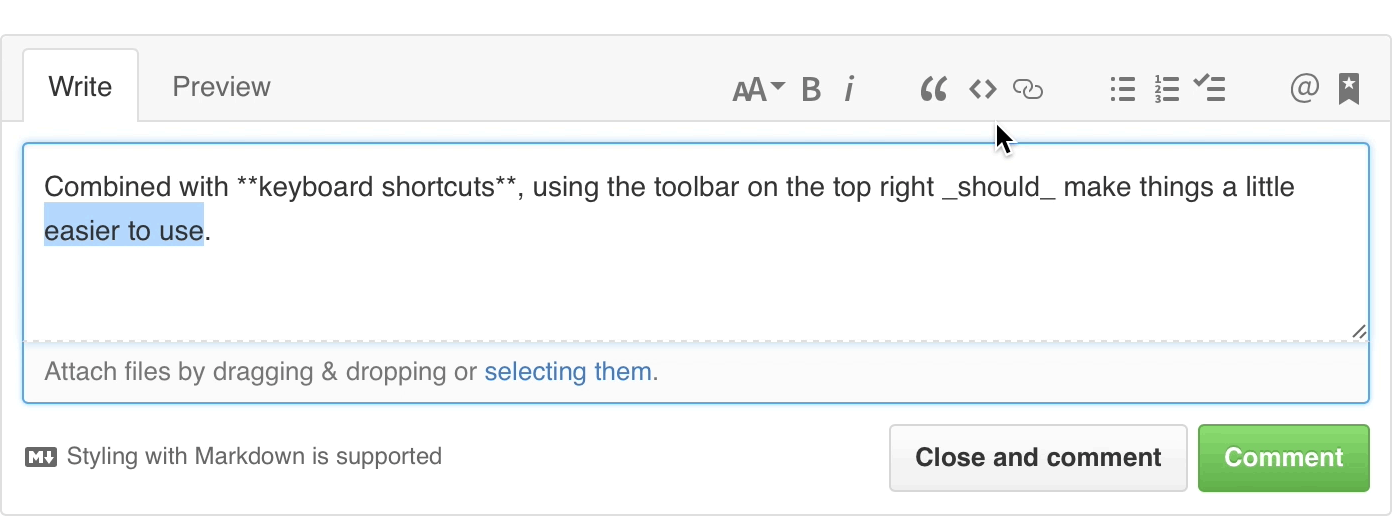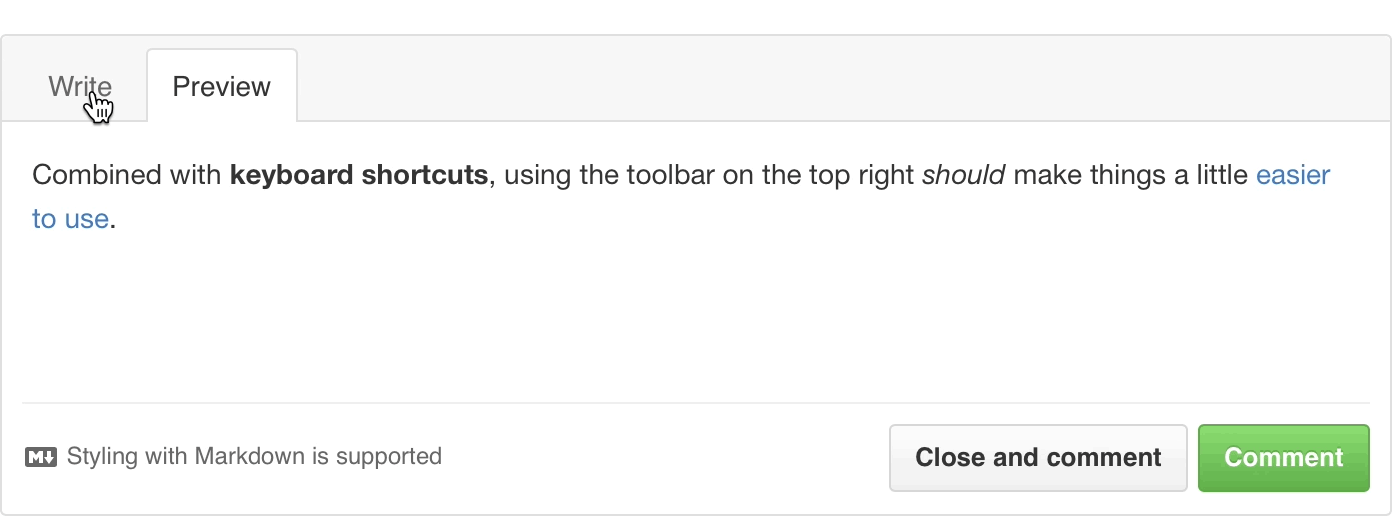
In addition to standard Markdown formatting, the toolbar also includes GitHub-specific features. @mentions bring additional users or teams into the conversation, issue and pull request links allow you to cross-reference related discussions, and task lists track outstanding tasks. They’re now available to you with a single click.
If your New Year's resolution was to update to a new version of Git, we've got good news. The Git community has just released Git 2.7.0, and we'd like to share some of its highlights with you.
git bisect
git bisect is an awesomely powerful tool for figuring out how a bug got into your project. Just in case you're unfamiliar with it, we'll take this opportunity to give you a short introduction. If you already know about git bisect, feel free to skip the following section.
git bisect
Suppose you get a bug report: "The hyperdrive is running backwards!" Sure enough, in the current master branch, the hyperdrive is running backwards:
$ git checkout master
$ ./test_hyperdrive
FAILURE: destination is getting farther away"That's funny," you think to yourself, "I know it worked in version 4.2." You double-check:
$ git checkout v4.2
$ ./test_hyperdrive
SUCCESS!The question is, how did it break? Some change between version 4.2 and master must have introduced a bug.
At this point you could open your debugger or start adding print statements to the hyperdrive module. But that's a lot of work. Luckily, there's an easier way to discover where the bug was introduced: git bisect.
You start by telling git bisect a good and a bad version:
$ git bisect start
$ git bisect good v4.2
$ git bisect bad master
Bisecting: 2 revisions left to test after this (roughly 1 step)
[8cc2d9b4f02ccc208bd9f6d6b01ac6ed57fbb606] Take advantage of available wormholesAs soon as you do so, git bisect chooses a revision roughly midway between the known-good and the known-bad revisions. Your job is to test this version then tell Git the result of your test:
$ ./test_hyperdrive
SUCCESS!
$ git bisect good
Bisecting: 0 revisions left to test after this (roughly 1 step)
[f97f670fb5303ea0097e4475ec8fcf3e2c7dde85] Hyperdrive: bypass the compressorYou continue like this, each time halving the gap between the newest known-good and the oldest known-bad revisions:
$ ./test_hyperdrive
SUCCESS!
$ git bisect good
Bisecting: 0 revisions left to test after this (roughly 0 steps)
[e0cbfe825a0285e58c59cefb9b78abff2ae0c369] Implement hyperdrive parity inverter
$ ./test_hyperdrive
FAILURE: destination is getting farther away
$ git bisect bad
e0cbfe825a0285e58c59cefb9b78abff2ae0c369 is the first bad commit
commit e0cbfe825a0285e58c59cefb9b78abff2ae0c369
Author: Some Developer <me@example.com>
Date: Thu Dec 31 14:05:09 2015 +0100
Implement hyperdrive parity inverter
:100644 100644 a9562e3d7cea826ed52072e9b104bc9f7e870cf9 da2bc4f6d15943dcf4872641fae08d79d7696512 A hyperdrive/parity.cCongratulations! You now know that commit e0cbfe8 introduced the bug. Often, viewing the changes made by that commit makes it obvious what the mistake was and how to fix it. If not, at least you've dramatically narrowed down the amount of code that you have to debug.
When you're done, type git bisect reset to end the bisection session.
git bisect: not just for regressions anymoreAlthough git bisect is most often used to find software regressions, it should be clear that the same approach can find any change that was introduced into the software; for example,
images directory grow beyond 5 MB?git bisect could always locate such changes. But regardless of what kind of change you were looking for, you always had to type good to mark revisions before the change and bad to mark revisions after the change. This could be very confusing, especially if you wanted to find the commit that fixed a bug1.
To better support such uses, git bisect now allows you to use different terms in place of good and bad. With no extra setup, you can now use the more neutral terms old and new to represent "the old state of affairs" and "the new state of affairs":
$ git bisect start
$ git bisect old v4.2
$ git bisect new masterYou can even invent your own terms. Just specify them when you start the bisection:
$ git bisect start --term-old yucky --term-new yummy
$ git bisect yucky v4.2
$ git bisect yummy master--recurse-submodules
If you use Git submodules, you have probably made the mistake of pushing changes to your main module without first pushing the corresponding changes that you made in your submodules. What you should have done, of course, is use the --recurse-submodules option; for example,
$ git push --recurse-submodules=on-demand originNow there is a new configuration option that you can use to save the extra typing (and the embarrassment of pushing incomplete work):
$ git config push.recurseSubmodules on-demandIf you'd rather have Git just warn you about potential problems, then use
$ git config push.recurseSubmodules checkYou can override this configuration setting by typing --no-recurse-submodules on the command line. [source]
worktree improvementsDo you remember the git worktree command that was introduced in Git 2.5.0? It allows you to create multiple working copies that are connected to a single local Git repository.
In Git 2.7.0, git worktree continues to get better:
git worktree list command, you can list the worktrees linked to the current repository and the branch checked out in each one. [source]
git bisect can now run in any worktree, or even in two worktrees simultaneously. [source]
git p4
git p4 is a bridge between Git and Perforce. It can fetch commits from Perforce into Git, and push commits from Git to a Perforce server. It allows you to use Git locally, even if you ultimately have to push your changes to a Perforce server. (There are similar tools to bridge between Git and Subversion, Mercurial, Bazaar, TFS, and others.)
git p4 now has support for storing large files in Git LFS ("Git Large File Storage"). This allows you to store large files from Perforce (e.g., media files) outside of your Git repository to avoid bloating the repository on disk. (Note that this feature doesn't yet support git p4 submit.) [source]
Git has three main ways to list references: git branch, for listing branches; git tag, for listing tags; and git for-each-ref, for listing references of any kind. But these commands, despite their overlapping functionality, had differing capabilities and options.
Now, thanks to the work of Google Summer of Code student Karthik Nayak, these commands now have a more uniform interface, and have also gained some features along the way. Now all three commands support the following options:
--points-at <object>: list any references that point at the specified object--merged [<commit>]: only list references that have been merged into commit (HEAD by default) :--no-merged [<commit>]: only list references that have not been merged into commit (HEAD by default) :--contains [<commit>]: only list references that contain the specified commit (HEAD by default)They have also gained new formatting and sorting options. [source] [source]
git stash show now supports two configuration settings, stash.showPatch and stash.showDiff, that select how it should display stash entries by default. [source]
git blame now works correctly with the --first-parent option, and also when --reverse and --first-parent are used together. [source] [source]
The appearance of gitk on high-DPI monitors has been improved. [source]
Security fixes:
We recommend that everybody upgrade to a version of Git with these fixes, namely Git 2.3.10+, 2.4.10+, 2.5.4+, 2.6.1+, or of course 2.7.0+.
As usual, if you would like to know more details about what is new in Git 2.7.0, please refer to the full release notes.
This Git release has more than 800 commits from 81 contributors. Here's to a great 2015 and an even better 2016!
[1] It might seem that git bisect shouldn't care whether the change you are looking for was from bad to good or from good to bad. But in fact, if the first two commits that you mark are not direct ancestor/descendant of each other, git bisect has to examine some common ancestors of those commits. In that case, the logic is different depending on the direction of the transaction that you are looking for.
If you're writing code, a repository is an obvious place to manage your work. But what about when the team's primary deliverable is not software? At GitHub, the Professional Services team helps customers get set up with GitHub Enterprise and trains people how to use Git and GitHub. We use GitHub extensively to efficiently and transparently communicate, schedule and prioritize. We hope how we use GitHub will help your team use the platform for more than just code.
Most teams at GitHub have a team repository with a README.md file that introduces the team and explains the team's main responsibilities. Our Services team's repository shows our offerings and introduces the members of our team.
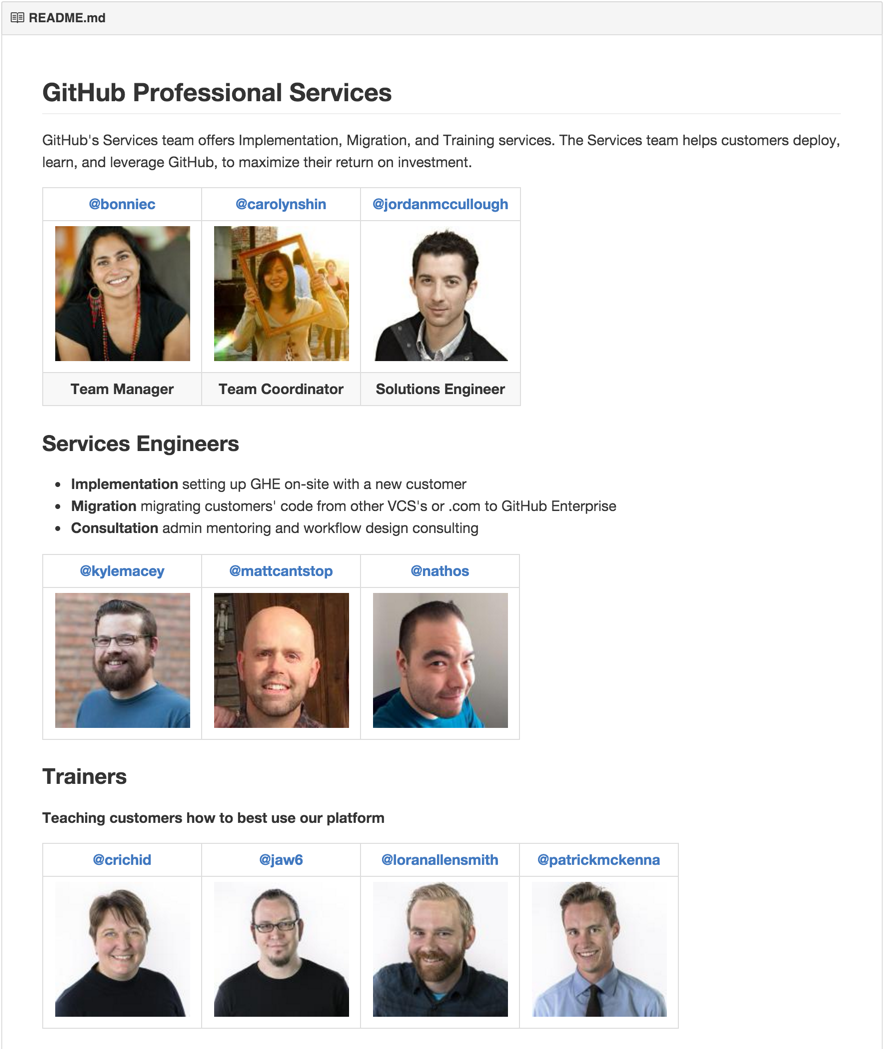
Our README provides a clear path forward for teams who want to utilize our services by listing our offerings and showing who to reach out to if help is needed. We provide specific team handles for people to mention us with GitHub's @mention feature. By mentioning a specific team they can reach the subset of the team they need.

This way, different team members can respond to their respective team handles. Some teams at GitHub rotate who is responsible for checking their team's mentions on a weekly basis. This lets some team members have stretches without distraction while the team is still responsive to GitHubbers outside of their team. We have streamlined many processes to utilize @mentions with GitHub's notifications instead of relying solely on email correspondence.
In our README, we also have linked Markdown files that document our services. We have files that document how we work, including everything from checklist-formatted Markdown files for onboarding new team members to guides on how to configure LDAP for our customers on GitHub Enterprise. Our team repository provides ample information for people to do their jobs.
GitHub Issues, Pull Requests and Notifications are at the heart of coordinating, delivering, and reviewing the Services team's engagements with customers. We use a link that has our engagement Issue template as the body parameter of the URL. This creates a checklist as the top comment of a newly created issue. We coordinate with Sales, Finance, and Legal by opening issues in their team's respective repositories.
Once an engagement is set and ready to be delivered we open a Pull Request to track delivery tasks and notes. We create a file called retrospective.md in a /engagements folder in the repository to open the Pull Request. We then use the top comment of our Pull Request to track any bugs, follow-up tasks for after the engagement, and leave notes for sales to take over. We add comments to the Pull Request for each day's notes to keep everyone on the team in the loop.
When we complete the engagement we write our retrospective. Many different teams at GitHub know about this folder and check in on customer feedback by visiting this /engagements folder and reviewing the retrospective files. We use Pull Request comments to add final details like our expenses and mention the teams needed to close out any outstanding tasks. The process lets us have a great historical document of our conversations instead of the details getting lost in people's email.
On the GitHub Professional Services team, we try to ensure the decision-making process and our team's initiatives are as collaborative and transparent as possible. We open an issue to discuss any topic that needs our attention. We try to default to having conversations in the open and with a URL.
Transparent conversation is especially necessary as a geographically-distributed team. This pattern permits others who are on Services engagements to get context when they finish their engagements and catch up on their notifications. It also lets people understand the why of a decision even years after the decision occurred.
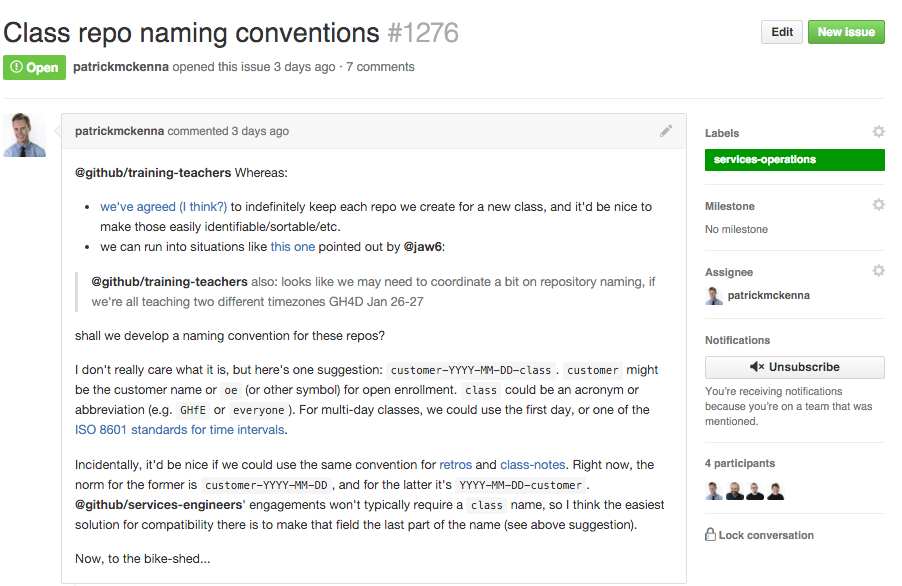
We often have lengthy discussions about which path to chose, and because we're a diverse team, we hear many different approaches. Our internal focus is to get to a point where we can move forward with an option to test, and refine the path forward as we get more information about what works best.
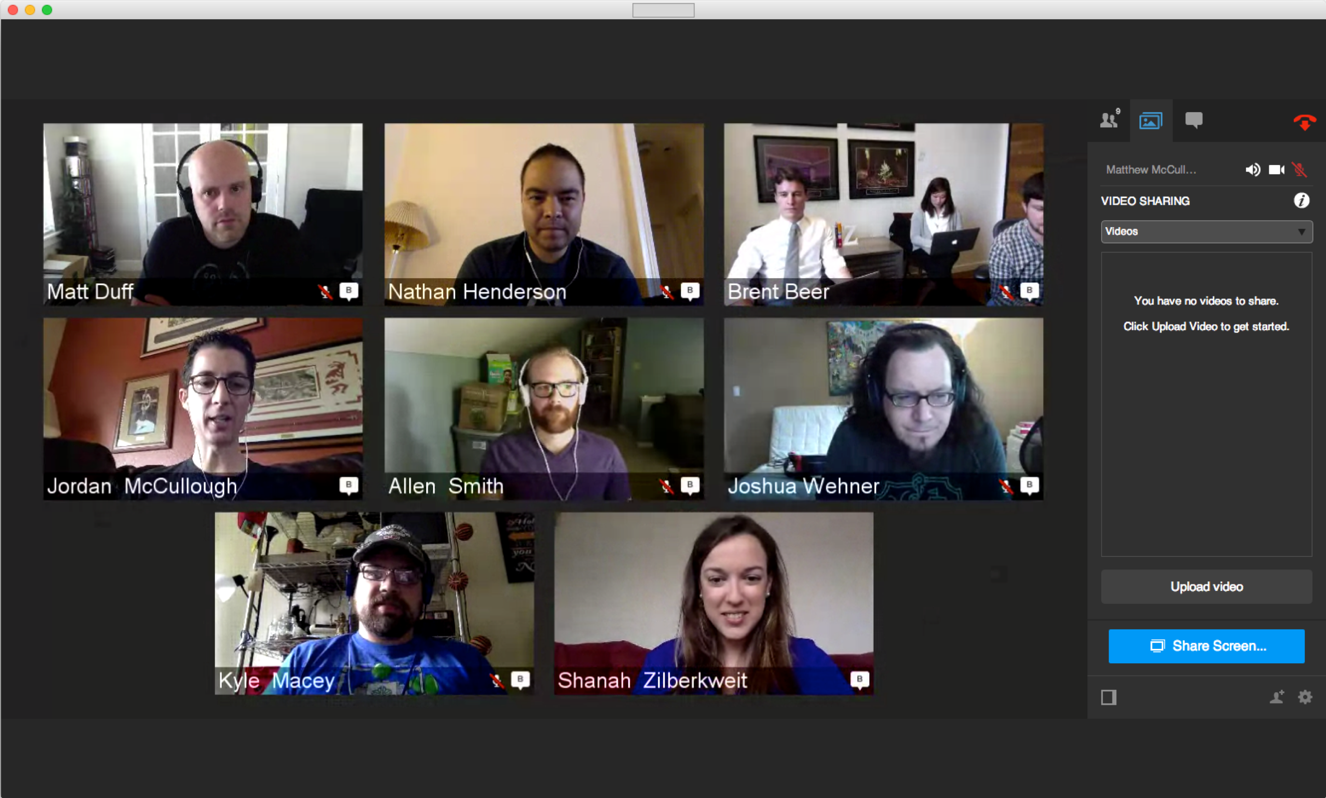
Each Monday, we create an issue that we use as our standup meeting. We add our availability for the week and the main items we will be focusing on. We get together for a 30-minute video chat session to collaborate on the week's activities and to spend some face-to-face time together. People add updates to their activities throughout the week in the radar issue. This helps us stay connected as a distributed team.
The Services team's uses of Pull Requests are varied. We tend to think of a pull request as shipping some change or accomplishment into our organization. We open pull requests to change our README, to track an engagement we are on and to propose future plans for the team. The pull request process enables us to get feedback from our team members while also tracking our major accomplishments. We use GitHub's checklist feature to track outstanding tasks for any deliverable (including this blog post).
Pull requests do a great job of showing how a document evolved as well as making that evolution a collaborative process. By editing files in a pull request, we can see how our thinking has changed over time or how our organization has grown. I attended a great session at OSCON Amsterdam about how New Relic uses Pull Requests for non-code deliverables as varied as discussing company policy changes to documenting infrastructure. Many of the companies that use GitHub discover how the simple @mention and notification tools can transform workflows and company culture.
At the heart of GitHub is a toolset that empowers developers through tracking change and enabling collaboration. The Services team at GitHub uses these tools as an integral part of their work to help move the company forward. How does GitHub help your team be more collaborative and productive?
The Services team is hiring for multiple positions. Check out the job board and see how you can help us enable companies to create great things with GitHub. If your team needs help getting the most out of GitHub you can visit our website to see our offerings.
We love the Ruby programming language for its natural, human-focused design philosophy and think you will too. That's why we teamed up with Udacity to bring you three new Ruby Nanodegrees, starting with Beginning Ruby.

Beginning Ruby is open for enrollment now, with Ruby on Rails and Senior Ruby on Rails becoming available in 2016.
In each of the Nanodegree programs you will learn from Udacity's expert instructors, with supplemental interviews and content from GitHub Ruby instructors Jesse Toth and John Britton.
With a commitment of 10-15 hours per week, students complete a Nanodegree in an average of 4-9 months, at a cost of $200 per month with 50% returned upon graduation in some cases.
Partnering with Udacity to create the Ruby Nanodegree series is a step to help close the talent gap and empower aspiring developers to gain new skills.
 Today GitHub is proud to host the Secretary of Housing and Urban Development, Julián Castro, at our SF office. We are thrilled to welcome him, his senior staff, community organizations, tech company workers, and representatives from EveryoneOn, the national non-profit leader of ConnectHome.
Today GitHub is proud to host the Secretary of Housing and Urban Development, Julián Castro, at our SF office. We are thrilled to welcome him, his senior staff, community organizations, tech company workers, and representatives from EveryoneOn, the national non-profit leader of ConnectHome.
ConnectHome stands alone as the first project of its kind. A public-private sector partnership, ConnectHome will initially connect more than 102,000 low-income households – and nearly 200,000 children – living in public housing with high speed broadband wireless Internet and tech tools for digital innovation.
As Chike Aguh from EveryoneOn stated at GitHub Universe, “Talent is universal, but opportunity is not.”
Growing up, many of us working in tech had a home Internet connection and a computer which jump-started our ability to be part of this sector: Currently, 1 in 4 US households do not have a home internet connection. This digital divide primarily affects low-income residents of color and has devastating effects on education and job attainment. Bridging the digital divide is a necessary ingredient to break generational cycles of poverty. GitHub understands this and we’re proud to be in on the ground floor of ConnectHome.
An investment in ConnectHome is an investment in the future of innovation. We will all reap the benefits of a country where everyone is connected and one in which those most impacted by systemic inequity will be the engineers, creators, leaders, and innovators of the tech sector. We fully expect to hire from this talent pool, and are ready and excited to support the genius on the ground.
Today we are proud to announce that we are doubling down on our financial commitment to ConnectHome - now $500,000 - along with $3 million in product and thousands of hours of staff time to help make this a reality. But we need your help: Join us in being part of this historic initiative.
Donate to the individual giving campaign to help every ConnectHome household with children get a device. Spread the word through your networks.
Today GitHub’s CEO, Chris Wanstrath, is issuing a challenge to our friends in the tech sector: Join us in putting dollars behind this momentous project. Contact us (ConnectHome@github.com) to become a company sponsor of ConnectHome.