Micro Platform 






The micro platform is a complete runtime for building and managing microservices at scale. Where micro provides the fundamental building blocks and core essentials, the platform goes a step further and addresses every requirement for large scale distributed system deployments. Monitoring, distributed tracing, authentication, dynamic configuration, label based routing, etc, etc.
This repository provides a unified entry point for running the individual platform services.
Use the go-platform client to leverage the platform.
Platform Services
| Repo | Description |
|---|---|
| auth-srv | Authentication and authorization (Oauth2) |
| config-srv | Dynamic configuration |
| db-srv | Database proxy |
| discovery-srv | Discovery read cache |
| event-srv | Event aggregation |
| monitor-srv | Monitoring for Status, Stats and Healthchecks |
| router-srv | Global service load balancing |
| trace-srv | Distributed tracing |
Platform Web Dashboards
| Repo | Description |
|---|---|
| config-web | Dynamic configuration dashboard |
| discovery-web | Service discovery dashboard |
| event-web | Event summarisation dashboard |
| monitor-web | Monitoring dashboard |
| trace-web | Distributed tracing dashboard |
Additional Services
There are a few other services that we support as part of the go-platform but haven't written backend services for. These are still vital for a microservice platform and we may build services for them later but there are very strong systems in the OSS world for them.
| Feature | Description |
|---|---|
| KV | Distributed Key Value |
| Sync | Distributed Synchronization |
| Log | Centralised logging |
| Metrics | Metrics aggregation and graphing |
Go-platform Features
| Package | Built-in Plugin | Description |
|---|---|---|
| auth | auth-srv | authentication and authorisation for users and services |
| config | config-srv | dynamic configuration which is namespaced and versioned |
| db | db-srv | distributed database abstraction |
| discovery | discovery-srv | extends the go-micro registry to add heartbeating, etc |
| event | event-srv | platform event publication, subscription and aggregation |
| kv | distributed in-memory | simply key value layered on memcached, etcd, consul |
| log | file | structured logging to stdout, logstash, fluentd, pubsub |
| monitor | monitor-srv | add custom healthchecks measured with distributed systems in mind |
| metrics | telegraf | instrumentation and collation of counters |
| router | router-srv | global circuit breaking, load balancing, A/B testing |
| sync | consul | distributed locking, leadership election, etc |
| trace | trace-srv | distributed tracing of request/response |
What's it even good for?
The Micro platform is useful for where you want to build a reliable globally distributed systems platform at scale. You would be in good company by doing so, with the likes of Google, Facebook, Amazon, Twitter, Uber, Hailo, etc, etc.
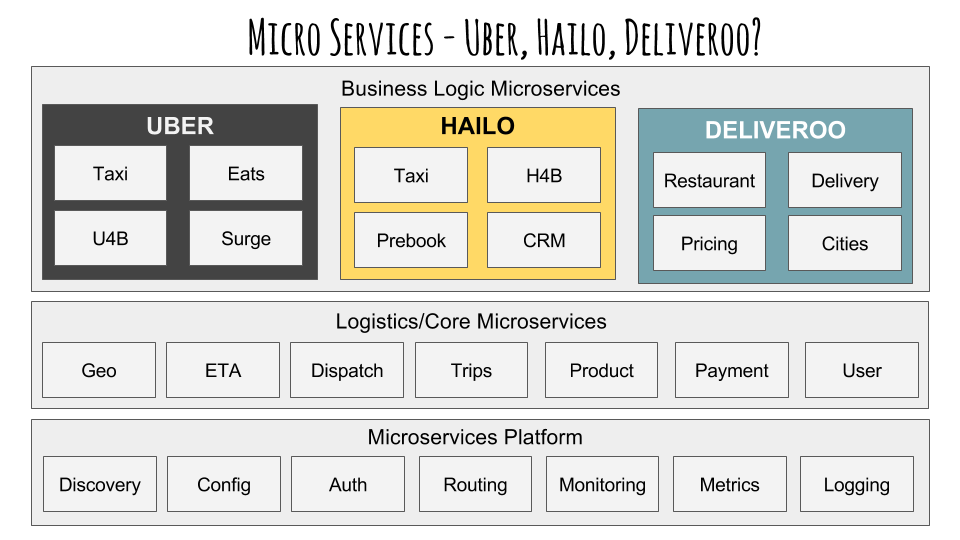
How does it work?
The go-platform is a client side interface for the fundamentals of a microservice platform. Each package connects to a platform service which handles that feature. Everything is an interface and pluggable which means you can choose how to architect your platform. Micro however provides a "platform" implementation backed by it's own services by default.
Each package can be used independently or integrated using go-micro client and handler wrappers.
Auth
Auth addresses authentication and authorization of services and users. The default implementation is Oauth2 with an additional policy engine coming soon. This is the best way to authenticate users and service to service calls using a centralised authority. Security is a first class citizen in a microservice platform.
Config
Config implements an interface for dynamic configuration. The config can be hierarchically loaded and merged from multiple sources e.g file, url, config service. It can and should also be namespaced so that environment specific config is loaded when running in dev, staging or production. The config interface is useful for business level configuration required by your services. It can be reloaded without needing to restart a service.
DB (experimental)
The DB interface is an experiment CRUD interface to simplify database access and management. The amount of CRUD boilerplate written and rewritten in a microservice world is immense. By offloading this to a backend service and using RPC, we eliminate much of that and speed up development. The platform implementation includes pluggable backends such as mysql, cassandra, elasticsearch and utilises the registry to lookup which nodes databases are assigned to.
This is purely experimental at this point based on some ideas from how Google, Facebook and Twitte do database management internally.
Discovery
Discovery provides a high level service discovery interface on top of the go-micro registry. It utilises the watcher to locally cache service records and also heartbeats to a discovery service. It's akin to the Netflix Eureka 2.0 architecture whereby we split the read and write layers of discovery into separate services.
Event
The event package provides a way to send platform events and essentially create an event stream and record of all that's happening in your microservice environment. On the backend an event service aggregates the records and allows you to subscribe to a specific set of events. An event driven architecture is a powerful concept in a microservice environment and must be addressed adequately. At scale it's essential for correlating events within a distributed system e.g provisioning of new services, change of dynamic config, logouts for customers, tracking notifications, alerts.
KV
KV represents a simple distributed key-value interface. It's useful for sharing small fast access bits of data amonst instances of a service. We provide three implementations currently. Memcached, redis and a consistently hashed in distributed in memory system.
Log
Log provides a structured logging interface which allows log messages to be tagged with key-value pairs. The default output plugin is file which allows many centralised logging systems to be used such as the ELK stack.
Monitor
The monitor provides a way to publish Status, Stats and Healtchecks to a monitoring service. Healthchecks are user defined checks that may be critical to a service e.g can access database, can sync from s3, etc. Monitoring in a distributed system is fundamentally different from the classic LAMP stack. In the old ways pings and tcp checks were regarded as enough, in a distributed system we require much more fine grained metrics and a monitoring service which can make sense of what failure means in this world.
Metrics
Metrics is an interface for instrumentation. We regard metrics as a superior form of observability in a distributed system over logging. Instrumentation is a great way to graph historic and realtime data which can be correlated and immediately understood. The metrics interface provides a way to create counters, gauges and histograms. We currently implement the statsd interface and offload to telegraf which provides an augmented statsd interface with labels.
Router
The router builds on the registry and selector to provide rate limiting, circuit breaking and global service load balancing. It implements the selector interface. Stats are recorded for every request and periodically published. A centralised routing service aggregates these metrics from all services in the environment and makes decisions about how to route requests. The routing service is not a proxy. Proxies are a weak form of load balancing, we prefer smart clients which retrieve a list of nodes from the router and make direct connections, this means if the routing service dies or misbehaves, clients can continue to make request independently.
Sync
Sync is an interface for distributed synchronisation. This provides an easy way to do leadership election and locking to serialise access to a resource. We expect there to be multiple copies of a service running to provide fault tolerance and scalability but it makes it much harder to deal with transactions or serialising access. The sync package provides a way to regain some of these semantics.
Trace
Trace is a client side interface for distributed tracing e.g dapper, zipkin, appdash. In a microservice world, a single request may fan out to 20-30 services. Failure may be non deterministic and difficult to track. Distributed tracing is a way of tracking the lifetime of a request. The interface utilises client and server wrappers to simplify using tracing.
Usage
$ platform
NAME:
platform - A microservices platform
USAGE:
platform [global options] command [command options] [arguments...]
VERSION:
latest
COMMANDS:
auth Auth commands
config Config commands
discovery Discovery commands
db DB commands
event Event commands
monitor Monitor commands
router Router commands
trace Trace commands
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--server_name Name of the server. go.micro.srv.example [$MICRO_SERVER_NAME]
--server_version Version of the server. 1.1.0 [$MICRO_SERVER_VERSION]
--server_id Id of the server. Auto-generated if not specified [$MICRO_SERVER_ID]
--server_address Bind address for the server. 127.0.0.1:8080 [$MICRO_SERVER_ADDRESS]
--server_advertise Used instead of the server_address when registering with discovery. 127.0.0.1:8080 [$MICRO_SERVER_ADVERTISE]
--server_metadata [--server_metadata option --server_metadata option] A list of key-value pairs defining metadata. version=1.0.0 [$MICRO_SERVER_METADATA]
--broker Broker for pub/sub. http, nats, rabbitmq [$MICRO_BROKER]
--broker_address Comma-separated list of broker addresses [$MICRO_BROKER_ADDRESS]
--registry Registry for discovery. memory, consul, etcd, kubernetes [$MICRO_REGISTRY]
--registry_address Comma-separated list of registry addresses [$MICRO_REGISTRY_ADDRESS]
--selector Selector used to pick nodes for querying. random, roundrobin, blacklist [$MICRO_SELECTOR]
--transport Transport mechanism used; http, rabbitmq, nats [$MICRO_TRANSPORT]
--transport_address Comma-separated list of transport addresses [$MICRO_TRANSPORT_ADDRESS]
--database_url The database URL e.g root@tcp(127.0.0.1:3306)/database [$MICRO_DATABASE_URL]
--register_ttl "0" Register TTL in seconds [$MICRO_REGISTER_TTL]
--register_interval "0" Register interval in seconds [$MICRO_REGISTER_INTERVAL]
--html_dir The html directory for a web app [$MICRO_HTML_DIR]
--help, -h show helpRunning a platform service
The platform consists of a number of services. They can be run in the following way. For example config srv.
$ platform --registry_address=192.168.99.100 --database_url="root@tcp(127.0.0.1:3306)/config" config srv
2016/03/15 21:04:26 Listening on [::]:62017
2016/03/15 21:04:26 Broker Listening on [::]:62018
2016/03/15 21:04:26 Registering node: go.micro.srv.config-803dcb2a-eaf1-11e5-806f-68a86d0d36b6Running a platform web service
The platform web services are a visual frontend for the service backends. They can be run in the following way.
$ platform --registry_address=192.168.99.100 --html_dir=/path/to/trace-web/templates trace web
Listening on [::]:60576Roadmap
- Micro {API, Web, CLI, SideCar} added with platform enhancements e.g auth, routing, etc
- Web services for each platform service
- CLI shortcuts for the platform
- Provisioning and dependency management